Umgang mit fehlenden Datenwerten bei der Datenbereinigung

Eine der größten Herausforderungen bei den meisten Business Intelligence (BI)-Projekten ist die Datenqualität (oder der Mangel daran). Tatsächlich verbringen die meisten Projektteams 60 bis 80 Prozent der gesamten Projektzeit mit der Bereinigung ihrer Daten - und das gilt sowohl für BI als auch für Predictive Analytics.
Um die Effektivität des Datenbereinigungsprozesses zu verbessern, geht der aktuelle Trend dahin, von der manuellen Datenbereinigung zu intelligenteren, auf maschinellem Lernen basierenden Prozessen überzugehen.
Identifizieren Sie die fehlenden Datenwerte
Bei den meisten Analyseprojekten gibt es drei mögliche Arten von fehlenden Datenwerten, je nachdem, ob es eine Beziehung zwischen den fehlenden Daten und den anderen Daten im Datensatz gibt:
- Völlig zufällig fehlende Daten (MCAR): In diesem Fall gibt es möglicherweise kein Muster dafür, warum die Daten in einer Spalte fehlen. Beispielsweise fehlen Umfragedaten, weil jemand einen Termin nicht wahrnehmen konnte oder weil ein Verwalter die Testergebnisse, die er in den Computer eingeben sollte, verlegt hat. Der Grund für die fehlenden Werte steht in keinem Zusammenhang mit den Daten im Datensatz.
- Fehlende Daten nach dem Zufallsprinzip (MAR): In diesem Szenario kann der Grund für die fehlenden Daten in einer Spalte durch die Daten in anderen Spalten erklärt werden. Zum Beispiel erhält ein Schüler, der über dem Grenzwert liegt, normalerweise eine Note. Eine fehlende Note für einen Schüler kann also durch die Spalte erklärt werden, in der die Werte unter dem Grenzwert liegen. Der Grund für diese fehlenden Werte kann durch Daten in einer anderen Spalte beschrieben werden.
- Nicht zufällig fehlende Werte (MNAR): Manchmal steht der fehlende Wert im Zusammenhang mit dem Wert selbst. Zum Beispiel geben Personen mit höherem Einkommen ihr Einkommen nicht an. In diesem Fall gibt es eine Korrelation zwischen den fehlenden Werten und dem tatsächlichen Einkommen. Die fehlenden Werte sind nicht von anderen Variablen im Datensatz abhängig.
Umgang mit fehlenden Datenwerten
Datenteams können eine Reihe von Strategien für den Umgang mit fehlenden Daten anwenden. Einerseits sind Algorithmen wie Random Forest und KNN robust im Umgang mit fehlenden Werten.
Andererseits müssen Sie möglicherweise selbst mit fehlenden Daten umgehen. Die erste gängige Strategie für den Umgang mit fehlenden Daten besteht darin, die Zeilen mit fehlenden Werten zu löschen. Normalerweise wird jede Zeile, die in einer Zelle einen fehlenden Wert enthält, gelöscht. Dies bedeutet jedoch oft, dass viele Zeilen entfernt werden, was zu einem Verlust von Informationen und Daten führt. Daher wird diese Methode in der Regel nicht verwendet, wenn es nur wenige Datenproben gibt.
Sie können die fehlenden Daten auch imputieren. Dies kann ausschließlich auf der Grundlage der Informationen in der Spalte mit den fehlenden Werten oder auf der Grundlage anderer Spalten im Datensatz erfolgen.
Schließlich können Sie Klassifizierungs- oder Regressionsmodelle verwenden, um fehlende Werte vorherzusagen.
Schauen wir uns diese drei Strategien genauer an:
1. Fehlende Werte in numerischen Spalten
Der erste Ansatz besteht darin, den fehlenden Wert mit einer der folgenden Strategien zu ersetzen:
- Ersetzen Sie ihn durch einen konstanten Wert. Dies kann ein guter Ansatz sein, wenn er in Absprache mit dem Fachexperten für die Daten, mit denen wir arbeiten, verwendet wird.
- Ersetzen Sie ihn durch den Mittelwert oder den Median. Dies ist ein guter Ansatz, wenn die Datenmenge klein ist, führt aber zu Verzerrungen.
- Ersetzen Sie sie durch Werte, indem Sie Informationen aus anderen Spalten verwenden.
In der nachstehenden Teilmenge des Arbeitnehmerdatensatzes fehlen in drei Zeilen Gehaltsdaten. Außerdem enthält der Datensatz die Spalten "Bundesland" und "Jahre der Berufserfahrung":
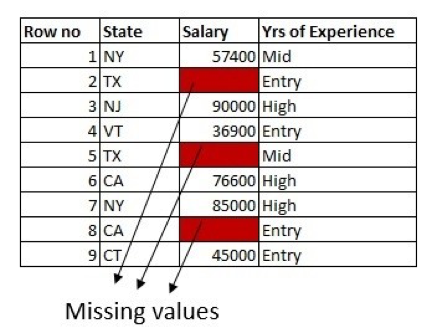
Der erste Ansatz besteht darin, die fehlenden Werte mit dem Mittelwert der Spalte aufzufüllen. Hier werden ausschließlich die Informationen aus der Spalte mit den fehlenden Werten verwendet:
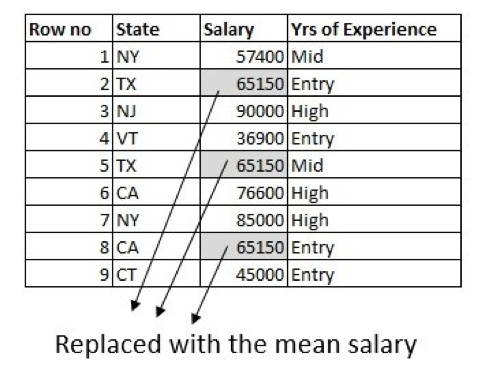
Mit Hilfe eines Fachmanns können wir die Informationen aus anderen Spalten des Datensatzes etwas besser nutzen. Das Durchschnittsgehalt ist für die verschiedenen Bundesstaaten unterschiedlich, so dass wir dies nutzen können, um die Werte aufzufüllen. Berechnen Sie z. B. das Durchschnittsgehalt von Personen, die in Texas arbeiten, und ersetzen Sie die fehlenden Daten durch das Durchschnittsgehalt von Personen, die normalerweise in Texas arbeiten:
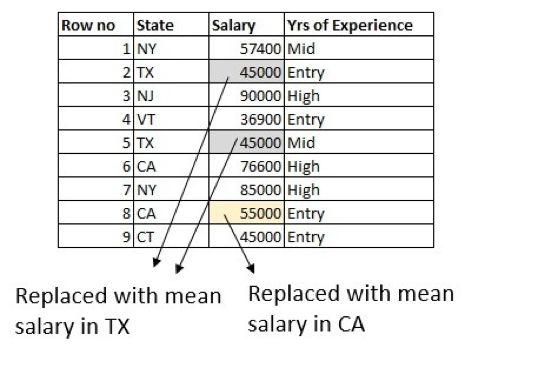
Was können wir noch besser machen? Wie wäre es, wenn wir auch die Spalte "Jahre der Erfahrung" nutzen würden? Berechnen Sie das durchschnittliche Einstiegsgehalt von Personen, die in Texas arbeiten, und ersetzen Sie die Zeile, in der das Gehalt für eine Person mit Einstiegserfahrung in Texas fehlt. Machen Sie dasselbe für die Gehälter auf mittlerer und hoher Ebene:
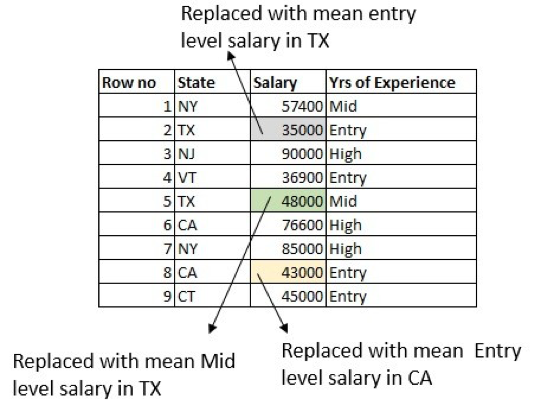
Beachten Sie, dass es einige Randbedingungen gibt. So kann es beispielsweise eine Zeile geben, in der sowohl in der Spalte "Gehalt" als auch in der Spalte "Jahre der Berufserfahrung" Werte fehlen. Es gibt mehrere Möglichkeiten, damit umzugehen, aber die einfachste ist, den fehlenden Wert durch das Durchschnittsgehalt in Texas zu ersetzen.
2. Vorhersage fehlender Werte mit Hilfe eines Algorithmus
Eine andere Möglichkeit, fehlende Werte vorherzusagen, ist die Erstellung eines einfachen Regressionsmodells. Die Spalte, die hier vorhergesagt werden soll, ist das Gehalt, wobei andere Spalten des Datensatzes verwendet werden. Wenn in den Eingabespalten fehlende Werte vorhanden sind, müssen wir diese Bedingungen bei der Erstellung des Vorhersagemodells berücksichtigen. Eine einfache Möglichkeit, dies zu bewerkstelligen, besteht darin, nur die Merkmale auszuwählen, die keine fehlenden Werte aufweisen, oder die Zeilen zu nehmen, die in keiner der Zellen fehlende Werte aufweisen.
3. Fehlende Werte in kategorialen Spalten
Der Umgang mit fehlenden Datenwerten in kategorialen Spalten ist viel einfacher als in numerischen Spalten. Ersetzen Sie den fehlenden Wert einfach durch einen konstanten Wert oder die am häufigsten verwendete Kategorie. Dies ist ein guter Ansatz, wenn die Datengröße klein ist, obwohl es zu Verzerrungen führt.
Ein Beispiel: Wir haben eine Spalte für Bildung mit zwei möglichen Werten: High School und College. Wenn es im Datensatz mehr Personen mit einem Hochschulabschluss gibt, können wir den fehlenden Wert durch College Degree ersetzen:
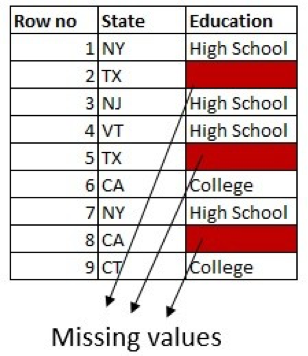
Wir können dies weiter optimieren, indem wir die Informationen in den anderen Spalten nutzen. Wenn beispielsweise mehr Personen aus Texas mit High School im Datensatz vorhanden sind, ersetzen Sie die fehlenden Werte in den Zeilen für Personen aus Texas mit High School.
Man kann auch ein Klassifizierungsmodell erstellen. Die Spalte, die hier vorhergesagt werden soll, ist Bildung, wobei andere Spalten des Datensatzes verwendet werden. Der gebräuchlichste und beliebteste Ansatz besteht jedoch darin, den fehlenden Wert in einer kategorialen Spalte als neue Kategorie namens Unbekannt zu modellieren:
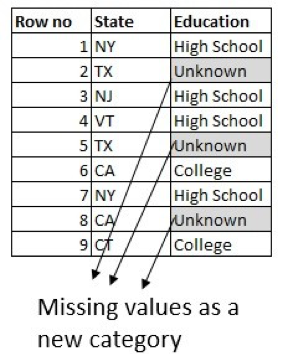
Zusammenfassend lässt sich sagen, dass Sie bei der Datenbereinigung je nach Art der Daten und des jeweiligen Problems unterschiedliche Ansätze für den Umgang mit fehlenden Werten verwenden werden. Wenn Sie Zugang zu einem Fachexperten haben, sollten Sie beim Auffüllen der fehlenden Werte immer dessen fachlichen Rat einbeziehen.
Am wichtigsten ist, dass Sie unabhängig von der gewählten Imputationsmethode immer das prädiktive Analysemodell ausführen, um zu sehen, welche Methode vom Standpunkt der Datengenauigkeit am besten funktioniert.

Der endgültige Leitfaden für prädiktive Analysen
Jetzt herunterladen: