MPP y bases de datos columnares

Muchas bases de datos SQL diseñadas para grandes volúmenes de datos se basan en arquitecturas de almacenamiento en columnas y procesamiento paralelo masivo (MPP).
¿Qué es una base de datos MPP?
Una base de datos MPP (Massively Parallel Processing) está diseñada para gestionar el procesamiento de datos a gran escala utilizando una arquitectura distribuida. A diferencia de SQL Server, que es un ejemplo de sistema de multiprocesamiento simétrico (SMP) que se basa en un único servidor con varios procesadores que comparten una memoria común, las bases de datos MPP distribuyen la carga de trabajo entre muchos servidores o nodos, cada uno con su propia memoria y procesadores.
Esta arquitectura paralela permite a las bases de datos MPP escalar horizontalmente, proporcionando un alto rendimiento para consultas complejas en grandes conjuntos de datos. Cada servidor de un sistema MPP procesa una parte de los datos simultáneamente, lo que acelera considerablemente las tareas de recuperación y análisis de datos. Como resultado, las bases de datos MPP son ideales para aplicaciones de big data y almacenes de datos en los que es necesario procesar grandes volúmenes de datos de forma rápida y eficiente.
En cambio, un sistema SMP como SQL Server suele estar limitado por la capacidad de un único servidor, lo que lo hace menos adecuado para operaciones de datos a muy gran escala. Mientras que SMP puede gestionar eficazmente cargas de trabajo moderadas, MPP ofrece una escalabilidad y un rendimiento superiores al aprovechar la potencia de varios servidores trabajando en paralelo.
Los sistemas MPP cuentan con varios servidores
La mayoría de las bases de datos MPP utilizan una "arquitectura compartida" en la que cada servidor funciona de forma independiente y controla su disco y su memoria. Distribuyen los datos en discos dedicados o unidades de almacenamiento de estado sólido (SSD) conectadas a cada servidor del dispositivo. (Un appliance de almacén de datos incluye un conjunto integrado de servidores, almacenamiento, sistemas operativos y bases de datos). Esto les permite resolver una consulta SQL explorando los datos en cada servidor de forma paralela. Este enfoque de divide y vencerás se amplía linealmente a medida que se añaden nuevos servidores a la arquitectura y ofrece un alto rendimiento.
¿Qué es una base de datos orientada a columnas?
Una base de datos orientada a columnas (o base de datos columnar) almacena los datos por columnas en lugar de por filas, que es como funcionan las bases de datos relacionales tradicionales. Este diseño permite almacenar y recuperar grandes conjuntos de datos con gran eficacia, sobre todo cuando se consultan unas pocas columnas en muchas filas.
En una base de datos orientada a columnas, todos los valores de una misma columna se almacenan juntos, lo que permite un rendimiento de lectura más rápido para las consultas analíticas que sólo necesitan acceder a columnas específicas. Esta arquitectura es especialmente adecuada para el almacenamiento de datos y las cargas de trabajo analíticas, en las que son habituales operaciones como la agregación, el filtrado y el escaneo de grandes conjuntos de datos. Además, los formatos de almacenamiento en columnas suelen lograr una mejor compresión de los datos, lo que mejora aún más el rendimiento y reduce los costes de almacenamiento.
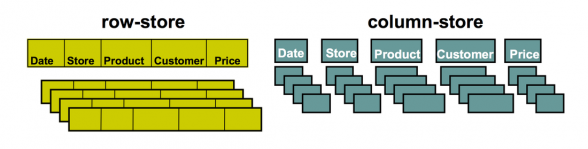
Para consultar grandes conjuntos de datos, las bases de datos de columnas son más eficaces que las de filas.
Los sistemas tradicionales de software de gestión de bases de datos relacionales diseñados para el procesamiento de transacciones almacenan los datos por filas, ya que esto proporciona la operación más eficiente a la hora de insertar, eliminar o actualizar una fila individual. En cambio, una base de datos orientada a columnas almacena las tablas de datos por columnas en lugar de por filas. Tanto las bases de datos de columnas como las de filas pueden utilizar lenguajes de consulta tradicionales como SQL para cargar datos y realizar consultas.
Sin embargo, uno de los principales cuellos de botella en el manejo de big data es el acceso al disco. Las bases de datos columnares mejoran el rendimiento reduciendo la cantidad de datos que hay que leer del disco mediante la compresión eficiente de datos columnares similares y la lectura únicamente de los datos necesarios para responder a la consulta.
Al almacenar los datos en columnas en lugar de en filas, la base de datos puede acceder y agregar más rápidamente los datos que necesita para responder a una consulta, en lugar de escanear y descartar los datos no deseados en las filas. Como resultado, los tipos de consultas agregadas que suelen utilizarse al analizar conjuntos de datos muy grandes se ejecutan mucho más rápido.
MPP frente a Hadoop
Cuando la mayoría de la gente piensa en big data, le vienen a la mente Hadoop y MapReduce, así como otros marcos de procesamiento modernos. ¿Significa eso que Hadoop sustituye a las bases de datos MPP? No, de hecho, existen sorprendentes similitudes entre la forma de trabajar de los tres.
Con Hadoop, MapReduce se utiliza para dividir grandes bloques de datos en lotes más pequeños que se procesan por separado a través de un clúster de nodos informáticos. Se trata de un procesamiento de consultas distribuido, que es exactamente lo que hace MPP.
El MPP suele desplegarse en hardware caro y especializado, ajustado en función del rendimiento de la CPU, el almacenamiento y la red. MapReduce y Hadoop suelen ejecutarse en clústeres de servidores que utilizan hardware básico (discos). Suele ser menos costoso escalar un despliegue Hadoop/MapReduce que un dispositivo MPP.
Además, la lógica de MapReduce se implementa mediante código Java, mientras que los productos MPP se consultan con SQL. Por supuesto, Hive ofrece una abstracción SQL sobre MapReduce. Pero nativamente, son diferentes a nivel de código. No obstante, tanto MPP como Hadoop/MapReduce pueden considerarse tecnologías de big data.
Logi Symphony en MPP y bases de datos columnares
Aunque Logi Symphony sobresale con big data y sus casos de uso, que para la mayoría de la gente son sinónimo de Hadoop, Logi Symphony no es sólo para big data. Las empresas orientadas a los datos tienen importantes activos de datos en bases de datos relacionales, almacenes de datos y otros sistemas tradicionales. Por esta razón, Logi Symphony también permite el descubrimiento de datos con fuentes tradicionales basadas en SQL como Oracle, SQL Server, PostgreSQL, MySQL, así como soluciones MPP como Amazon Aurora y bases de datos de almacenamiento en columnas como Vertica, Teradata y otras.
Logi Symphony y bases de datos SQL
Logi Symphony ofrece compatibilidad certificada con las siguientes bases de datos SQL, entre otras:
-
- MemSQL
- Vertica
- Teradata Database (on-premise) y Teradata Database en AWS
- Teradata Appliance para Hadoop en Cloudera CDH y Hortonworks HDP
- Microsoft SQL Server
- Base de datos Oracle
- PostgreSQL
- MySQL
Las arquitecturas de datos empresariales casi siempre contienen una combinación de fuentes de bases de datos SQL, así como fuentes modernas como Apache Hadoop y Apache Spark. Logi Symphony permite explorar todas estas fuentes de datos con la capacidad de combinar datos sobre la marcha mediante Logi Symphony.
Las funciones exclusivas de Logi Symphony que permiten el análisis visual de big data también pueden aplicarse a los datos tradicionales. Por ejemplo, Logi Symphony puede combinar fuentes modernas y tradicionales sin tener que mover los datos a un almacén de datos común. Data Sharpening, las microconsultas, el almacenamiento en caché de conjuntos de resultados y Data DVR añaden rendimiento y capacidades adicionales para el análisis visual en fuentes de datos SQL tradicionales.

Conozca Logi Composer
Ver ahora