¿Cuál es la diferencia? Bases de datos relacionales y no relacionales
¿Cuál es la diferencia entre una base de datos relacional y una no relacional? Un sistema de gestión de bases de datos relacionales (RDBMS) organiza los datos en tablas separadas, lo que permite un acceso flexible y un reensamblaje según tablas relacionales definidas por el usuario. En cambio, una base de datos no relacional emplea una arquitectura que no se basa en tablas como estructura principal.
Imagina que tus datos son un perro. Frente a él, colocas una hoja de Excel y un documento de Word. ¿A cuál se dirigirá el perro?
Puede resultar un poco absurdo, pero es una buena forma de entender exactamente qué tipo de datos funcionan con los dos tipos principales de bases de datos: relacionales y no relacionales. Vamos a repasar la diferencia entre las bases de datos relacionales y los sistemas de bases de datos no relacionales, así como a enumerar algunas preguntas clave que toda empresa debería plantearse antes de elegir una base de datos relacional frente a una no relacional.
Bases de datos relacionales y no relacionales
La diferencia entre bases de datos relacionales y no relacionales refleja las distinciones fundamentales en los sistemas de gestión de datos. Las bases de datos relacionales organizan los datos en tablas interrelacionadas, utilizando un formato estructurado que define filas y columnas dentro de un esquema, y se basan en SQL (Structured Query Language) para realizar consultas estructuradas. Esta configuración es ideal para requisitos de datos muy estructurados en los que la integridad de los datos y las capacidades de consulta complejas son esenciales. Las bases de datos relacionales destacan en el manejo de datos estructurados y garantizan la coherencia y precisión de las entradas de datos mediante relaciones predefinidas entre tablas. Esto las hace idóneas para aplicaciones en sectores como las finanzas, la sanidad y los sistemas ERP, en los que son necesarias la precisión y coherencia de los datos y la compatibilidad con complejas operaciones de unión.
Por otro lado, las bases de datos no relacionales, o bases de datos NoSQL, ofrecen soluciones de almacenamiento flexibles que pueden acomodar diversos tipos de datos, como documentos, pares clave-valor, almacenes de familias de columnas y estructuras de grafos. Esta flexibilidad es ventajosa cuando se trata de datos no estructurados o semiestructurados que no encajan perfectamente en un esquema rígido. Las bases de datos NoSQL están diseñadas para manejar aplicaciones escalables y soportar clusters distribuidos, lo que les permite gestionar grandes volúmenes de datos y elevadas cargas de tráfico. Esta escalabilidad y adaptabilidad hacen de las bases de datos no relacionales una opción ideal para aplicaciones que requieren un desarrollo rápido y pueden beneficiarse de un diseño sin esquemas, como las plataformas de medios sociales, las redes IoT y los sistemas de gestión de contenidos.
La elección entre bases de datos relacionales y no relacionales depende en última instancia de la necesidad de integridad de los datos estructurados y consultas complejas o de la necesidad de escalabilidad y flexibilidad en el manejo de los datos. Las bases de datos relacionales son las más adecuadas para los casos en los que la estructura y la integridad de los datos son fundamentales, mientras que las no relacionales destacan en entornos en los que la flexibilidad, la escalabilidad rápida y el manejo de distintos tipos de datos son más importantes.
¿Qué son las bases de datos relacionales?
Volvamos a tu "perro de datos". Quizá prefiera la hoja Excel. ¿Por qué? Porque encaja bien en filas y columnas.
Una base de datos relacional es aquella que almacena los datos en tablas. La relación entre cada punto de datos es clara y la búsqueda a través de esas relaciones es relativamente fácil. La relación entre tablas y tipos de campo se denomina esquema. En las bases de datos relacionales, el esquema debe estar claramente definido. Desde la perspectiva de una base de datos relacional, ser una parte integral de la arquitectura de 3 niveles pone de relieve su papel fundamental para garantizar la integridad de los datos, la seguridad y la gestión eficaz de los datos dentro de la Capa de Datos de la aplicación.
Las bases de datos relacionales son especialmente eficaces para gestionar datos estructurados, que deben encajar perfectamente en campos y filas predefinidos. Al basarse en esquemas, las bases de datos relacionales imponen una estricta coherencia de los datos, lo que ayuda a garantizar que todas las entradas de datos se adhieren a un formato específico y mantienen la integridad. Esta estructura hace que las bases de datos relacionales sean muy adecuadas para sectores que requieren precisión y fiabilidad, como las finanzas, la sanidad y la logística, donde la validación de los datos es fundamental para las operaciones cotidianas.
Uno de los principales puntos fuertes de las bases de datos relacionales es su compatibilidad con consultas complejas y operaciones de unión. SQL ofrece potentes funciones de consulta que permiten recuperar y combinar datos de varias tablas basándose en relaciones específicas, lo que permite realizar análisis en profundidad y elaborar informes. Esta capacidad es especialmente útil en los sistemas de gestión de relaciones con los clientes (CRM) y de planificación de recursos empresariales (ERP), en los que a menudo hay que reunir datos de distintas áreas para obtener una imagen completa.
Las bases de datos relacionales también soportan las propiedades ACID (Atomicidad, Consistencia, Aislamiento, Durabilidad), esenciales para mantener la fiabilidad de las transacciones. Estas propiedades evitan las actualizaciones parciales, garantizando que se completen todas las partes de una transacción o ninguna, lo que hace que las bases de datos relacionales sean ideales para aplicaciones críticas en las que la exactitud de los datos no es negociable.
En general, el enfoque estructurado y basado en esquemas de las bases de datos relacionales, combinado con sus sólidas capacidades de consulta y transacción, las convierte en una herramienta fundamental para aplicaciones que dependen de la integridad de los datos, una estructura coherente y un análisis complejo.
Veamos un ejemplo:
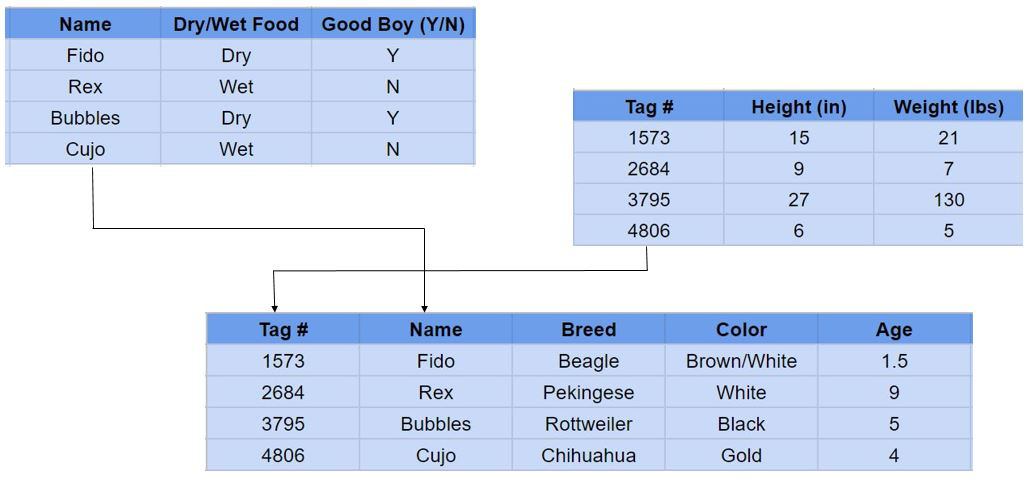
Aquí vemos tres tablas, todas ellas con información única sobre un perro concreto. Un usuario de una base de datos relacional puede obtener una vista de la base de datos que se ajuste a sus necesidades. Por ejemplo, podría querer ver o hacer un informe sobre todos los perros de más de 100 libras. O puede que desee ver qué razas comen pienso seco. Las bases de datos relacionales hacen que responder a preguntas como éstas sea relativamente fácil.
Las bases de datos relacionales también se denominan bases de datos SQL. SQL son las siglas de Structured Query Language (lenguaje de consulta estructurado) y es el lenguaje en el que están escritas las bases de datos relacionales. SQL se utiliza para ejecutar consultas, recuperar datos y editar datos actualizando, eliminando o creando nuevos registros.
La adopción temprana y el uso generalizado hacen que las bases de datos SQL sigan siendo un sistema popular de gestión de datos. Esto se debe en parte a la falta de formación necesaria para los trabajadores, ya que muchos científicos de datos aprenden SQL desde el principio. Hagamos un desglose más detallado de las bases de datos relacionales frente a las no relacionales.
Ejemplos de bases de datos relacionales/SQL populares
Servidor SQL
![]()
SQL Server es un sistema de gestión de bases de datos relacionales desarrollado por Microsoft. Los sistemas de gestión de bases de datos relacionales ofrecen múltiples ediciones con distintas características para dirigirse a diferentes usuarios.
Ventajas: SQL Server cuenta con una rica interfaz de usuario y puede manejar grandes cantidades de datos.
Contras: Puede ser caro, ya que el nivel Enterprise cuesta miles de dólares.
MySQL
![]()
Publicado por primera vez en 1995, MySQL es un software gratuito y de código abierto, y una de las bases de datos más populares del mundo. La utilizan muchos sitios web de gran tráfico, como Facebook y YouTube.
Ventajas: Es gratuito y de código abierto. También hay mucha documentación y soporte en línea.
Contras: No escala muy bien. MySQL tiende a dejar de funcionar cuando se le dan demasiadas operaciones en un momento dado.
PostgreSQL
![]()
Mientras que MySQL se basa en el modelo relacional, PostgreSQL se basa en el modelo objeto-relacional. Otra base de datos gratuita y de código abierto, PostgreSQL, se lanzó en 1996 haciendo hincapié en la extensibilidad. Es capaz de manejar cargas de trabajo de datos complicadas gracias a sus diversas funciones de extensión.
Ventajas: Como hemos dicho, extensible. Si necesitas características adicionales en PostgreSQL, puedes añadirlas tú mismo - una tarea difícil en la mayoría de las bases de datos.
Contras: Para los principiantes, la instalación y configuración pueden resultar difíciles. Tampoco hay tanta documentación como en bases de datos más populares como MySQL.
¿Qué son las bases de datos no relacionales?
De vuelta a su "perro de datos". Esta vez, se fue al documento de Word. ¿Por qué? Porque hay mucho espacio libre. Los datos vienen en diferentes formas y tamaños - necesitan espacio para extenderse.
Una base de datos no relacional es cualquier base de datos que no utilice el esquema tabular de filas y columnas de las bases de datos relacionales. En cambio, su modelo de almacenamiento está optimizado para el tipo de datos que almacena, lo que permite almacenar datos en diversos formatos, como documentos, pares clave-valor, gráficos o columnas. Esta flexibilidad en la estructura hace que las bases de datos no relacionales sean ideales para aplicaciones con datos en evolución o no estructurados que no encajan perfectamente en categorías predefinidas.

Las bases de datos no relacionales también se conocen como bases de datos NoSQL, que significa "No Sólo SQL". Mientras que las bases de datos relacionales se basan únicamente en SQL para la gestión de datos, las bases de datos no relacionales pueden utilizar otros lenguajes de consulta, a menudo específicos de su modelo de datos. Esta capacidad multilingüe permite a las bases de datos NoSQL manejar los datos de formas adaptadas a los distintos tipos de almacenamiento, mejorando el rendimiento y la escalabilidad para casos de uso específicos.
Existen cuatro tipos diferentes de bases de datos NoSQL:
Las bases de datos no relacionales son especialmente valiosas cuando se trabaja con datos a gran escala, complejos o que cambian rápidamente. Admiten varios modelos de datos, como:
1. Bases de datos documentales
- Estas bases de datos, como MongoDB y CouchDB, almacenan los datos como documentos (a menudo en formato JSON o BSON), lo que facilita la gestión de datos complejos y jerárquicos dentro de un único registro. Este modelo es especialmente útil para los sistemas de gestión de contenidos, donde cada documento puede tener estructuras y campos únicos.
2. Almacenes clave-valor
- Las bases de datos como Redis y DynamoDB utilizan un modelo sencillo en el que cada elemento se almacena como un par clave-valor, lo que permite una rápida recuperación de los datos. Los almacenes de clave-valor son ideales para el almacenamiento en caché y la gestión de sesiones debido a su alta velocidad de acceso.
3. Tiendas columna-familia
- Bases de datos como Cassandra y HBase almacenan datos por columnas en lugar de filas, lo que las hace eficientes para manejar grandes cantidades de datos estructurados a través de sistemas distribuidos. Este modelo es habitual en las aplicaciones de análisis de datos, en las que las operaciones suelen realizarse en columnas en lugar de en filas.
4. Bases de datos gráficas
- Bases de datos como Neo4j y Amazon Neptune se centran en las relaciones entre puntos de datos, lo que resulta especialmente útil en redes sociales, motores de recomendación y detección de fraudes. Al modelar las entidades como nodos y las relaciones como aristas, las bases de datos de grafos permiten gestionar y consultar de forma eficiente datos complejos e interconectados.
Las bases de datos no relacionales también están diseñadas para ofrecer escalabilidad y flexibilidad. A diferencia de las bases de datos tradicionales, que a menudo requieren un escalado vertical (añadir más potencia a un único servidor), las bases de datos NoSQL suelen permitir un escalado horizontal distribuyendo los datos entre varios servidores. Este enfoque distribuido permite a las aplicaciones manejar volúmenes de datos masivos y altas cargas de tráfico, proporcionando una forma rentable de escalar a medida que crecen las demandas de datos. Esta característica hace que las bases de datos no relacionales sean la opción preferida para aplicaciones nativas de la nube, análisis en tiempo real y entornos de big data.
Las bases de datos NoSQL también ofrecen una gran adaptabilidad para un desarrollo ágil. En aplicaciones donde los modelos de datos evolucionan con frecuencia o necesitan acomodar nuevos tipos de datos rápidamente, las bases de datos no relacionales ofrecen un diseño sin esquemas que simplifica el desarrollo. Esta flexibilidad permite a los equipos realizar ajustes sin tiempos de inactividad ni migraciones complejas, lo que convierte a las bases de datos NoSQL en una opción atractiva para startups, MVP (productos mínimos viables) y proyectos en los que la iteración rápida es esencial.
En general, las bases de datos no relacionales ofrecen una solución potente, escalable y flexible para aplicaciones que gestionan diversos tipos de datos, datos de alta velocidad y relaciones complejas. Su capacidad para gestionar datos no estructurados de forma eficiente y escalar con facilidad las convierte en una tecnología fundamental para las aplicaciones modernas basadas en datos.
Ejemplos de bases de datos no relacionales/NoSQL populares
MongoDB
![]()
MongoDB es un almacén de documentos y actualmente el motor de bases de datos NoSQL más popular en uso. Utiliza documentos de tipo JSON para almacenar datos y se ejecuta en varios servidores. MongoDB permite el auto-sharding, que es un tipo de particionamiento de bases de datos que separa bases de datos muy grandes en partes más pequeñas, rápidas y fáciles de gestionar, llamadas fragmentos de datos.
Ventajas: MongoDB es muy fácil de configurar y ofrece mucho soporte profesional.
Contras: No permiten las uniones. Las uniones se utilizan para combinar datos o filas de dos o más tablas basándose en un campo común entre ellas. MongoDB tiene una función LOOKUP pero dice a sus usuarios que no confíen en ellas.
Redis
![]()
Redis - Remote Dictionary Server - es un almacén de claves y valores. Admite distintos tipos de estructuras de datos abstractas, como cadenas, listas, mapas, conjuntos, conjuntos ordenados y más. También es de código abierto.
Ventajas: Admite una gran variedad de tipos de datos y es fácil de instalar.
Contras: Al igual que MongoDB, no soporta joins. También requiere conocimientos de Lua, un lenguaje de programación de alto nivel.
Cuándo utilizar bases de datos relacionales o no relacionales
A la hora de decidir entre bases de datos relacionales y no relacionales para su proyecto, es esencial tener en cuenta las necesidades y características específicas de sus datos, así como la forma en que piensa utilizarlos. A continuación analizamos en detalle las situaciones en las que una puede ser preferible a la otra:
Cuándo utilizar bases de datos relacionales
Las bases de datos relacionales son una potente opción para la gestión de datos cuando se requiere un alto nivel de estructura, coherencia e integridad de los datos. Con un esquema bien definido y relaciones de datos estrictas, las bases de datos relacionales sobresalen en aplicaciones donde la precisión de los datos y las consultas sofisticadas son primordiales.
Requisitos de los datos estructurados
Las bases de datos relacionales son la opción preferida cuando se trata de datos muy estructurados que siguen un formato coherente. En escenarios en los que cada dato encaja perfectamente en filas y columnas predefinidas, las bases de datos relacionales permiten una organización precisa y la validación de la entrada de datos. Esta estructura es ideal para aplicaciones empresariales, sistemas transaccionales y cualquier entorno en el que pueda establecerse por adelantado un esquema detallado. Las bases de datos relacionales refuerzan la integridad de los datos mediante reglas de esquema, lo que garantiza que los datos permanezcan coherentes y organizados en todas las tablas.
Consultas complejas y operaciones de unión
Las bases de datos relacionales están diseñadas para gestionar consultas complejas que abarcan varias tablas y requieren operaciones de unión avanzadas. Cuando las aplicaciones necesitan recuperar datos de distintas tablas con condiciones precisas, las bases de datos relacionales ofrecen un sólido soporte a través del lenguaje de consulta estructurado (SQL). Por ejemplo, en sistemas como las plataformas de gestión de las relaciones con los clientes (CRM) o los informes financieros, en los que los datos están interconectados y a menudo se consultan de forma sofisticada, las bases de datos relacionales permiten una ejecución eficaz y precisa de las consultas.
Transacciones ACID
Las bases de datos relacionales admiten transacciones ACID (Atomicity, Consistency, Isolation, Durability), un conjunto de propiedades que garantiza un tratamiento fiable de los datos en procesos de varios pasos. Estas propiedades son esenciales para aplicaciones en campos como las finanzas, la banca y el comercio electrónico, donde es fundamental un alto grado de precisión y coherencia de los datos. Al soportar transacciones ACID, las bases de datos relacionales mantienen la integridad de los datos incluso en caso de errores o caídas del sistema, lo que las hace adecuadas para aplicaciones de misión crítica en las que la precisión de los datos no es negociable.
Herramientas y ecosistema maduros
Tras décadas de desarrollo, las bases de datos relacionales cuentan con un ecosistema bien establecido de herramientas, soporte y recursos. Esta madurez ofrece amplias soluciones para la copia de seguridad, la supervisión y la optimización del rendimiento de los datos. Herramientas como Oracle Database, MySQL y Microsoft SQL Server cuentan con un sólido soporte comunitario y comercial, lo que permite una fácil integración con plataformas analíticas, herramientas de inteligencia empresarial y procesos ETL (Extract, Transform, Load). Este ecosistema establecido simplifica las operaciones y proporciona fiabilidad a los entornos empresariales que requieren soluciones de datos estables y a largo plazo.
Cuándo utilizar bases de datos no relacionales
Las bases de datos no relacionales, o bases de datos NoSQL, ofrecen la flexibilidad y escalabilidad necesarias para gestionar conjuntos de datos diversos y en rápido crecimiento. Están diseñadas para manejar estructuras de datos variables, lo que las hace ideales para aplicaciones con necesidades de desarrollo rápido y requisitos de datos a gran escala.
Modelos de datos flexibles
Las bases de datos no relacionales son idóneas para manejar datos no estructurados o semiestructurados, ya que ofrecen una flexibilidad de la que carecen las bases de datos relacionales. No requieren un esquema rígido, lo que permite que las estructuras de datos evolucionen con el tiempo sin modificar la estructura de la base de datos. Esto hace que las bases de datos NoSQL sean una opción excelente para aplicaciones con diversas fuentes de datos, como las plataformas de redes sociales, donde los formatos de datos pueden variar y adaptarse en función de las nuevas funciones o del contenido generado por los usuarios.
Escalabilidad
Las bases de datos NoSQL están diseñadas para escalar horizontalmente, lo que significa que pueden distribuir datos entre varios servidores o clústeres. Esto las hace muy eficaces para aplicaciones que prevén grandes volúmenes de datos y tráfico, como las aplicaciones web a gran escala o las plataformas IoT. Al aprovechar los sistemas distribuidos, las bases de datos no relacionales permiten un escalado rentable sin las limitaciones de las bases de datos relacionales tradicionales de escalado vertical. Esta escalabilidad es beneficiosa para las empresas que esperan un rápido crecimiento o que manejan escenarios de big data.
Alto rendimiento con consultas sencillas
Para aplicaciones con patrones de consulta sencillos y necesidades de alto rendimiento, las bases de datos no relacionales son una solución óptima. En casos como el almacenamiento en caché, la gestión de sesiones o la entrega de contenidos, las bases de datos NoSQL, como los almacenes de valores clave y las bases de datos de documentos, ofrecen capacidades de lectura y escritura rápidas. Esta velocidad es especialmente útil para aplicaciones en tiempo real en las que la latencia debe ser mínima y la recuperación de datos simple y directa es una prioridad.
Desarrollo rápido
La estructura sin esquema de las bases de datos NoSQL permite una rápida iteración, lo que las hace ideales para proyectos en los que el modelo de datos puede evolucionar con el tiempo. En entornos de desarrollo ágiles, en los que se añaden funciones con frecuencia y los requisitos de datos cambian, las bases de datos no relacionales permiten a los desarrolladores ajustar rápidamente las estructuras de datos sin las restricciones de un esquema rígido. Esta flexibilidad hace de las bases de datos NoSQL una opción atractiva para startups, MVPs (productos mínimos viables) y otras aplicaciones con necesidades de datos cambiantes.
Las bases de datos no relacionales ofrecen la flexibilidad y el rendimiento que exigen las aplicaciones modernas con gran cantidad de datos, por lo que resultan esenciales para escalar de forma dinámica y adaptarse a los requisitos cambiantes.
Base de datos relacional frente a base de datos no relacional: Ventajas e inconvenientes
A la hora de decidir entre bases de datos relacionales y no relacionales, es fundamental conocer los puntos fuertes y las limitaciones de cada tipo. Ambos tipos de bases de datos ofrecen ventajas únicas, por lo que la mejor elección depende de los requisitos específicos de la aplicación y de las necesidades de tratamiento de datos.
Ventajas e inconvenientes de las bases de datos relacionales
Pros:
- Integridad y coherencia de los datos: Las bases de datos relacionales imponen la exactitud de los datos mediante esquemas estrictos y el cumplimiento de ACID, lo que las hace ideales para aplicaciones en las que la integridad de los datos es fundamental, como las finanzas y la sanidad.
- Funciones de consulta complejas: SQL permite realizar potentes consultas y uniones entre varias tablas, lo que posibilita un análisis detallado y una recuperación de datos compleja. Esto hace que las bases de datos relacionales sean idóneas para la elaboración de informes y tareas analíticas.
- Ecosistema maduro: Las bases de datos relacionales tienen una larga historia, lo que se traduce en un sólido soporte, herramientas y recursos para copias de seguridad, supervisión y optimización, lo que las hace muy fiables en entornos empresariales.
Contras:
- Esquema rígido: Las bases de datos relacionales requieren un esquema predefinido, lo que puede dificultar su adaptación a las necesidades cambiantes de los datos o dar cabida a datos no estructurados.
- Limitaciones de escalabilidad: La mayoría de las bases de datos relacionales se basan en el escalado vertical (añadir más potencia a un único servidor), lo que puede resultar costoso y menos eficiente para aplicaciones a gran escala.
- Rendimiento con grandes volúmenes de datos: Las bases de datos relacionales pueden experimentar cuellos de botella de rendimiento cuando se enfrentan a volúmenes de datos masivos o altas velocidades de escritura, lo que las hace menos adecuadas para análisis en tiempo real o entornos de big data.
Ventajas e inconvenientes de las bases de datos no relacionales
Pros:
- Flexibilidad en la estructura de datos: Las bases de datos no relacionales utilizan diseños sin esquema, lo que permite un almacenamiento de datos más flexible y adaptable. Esto resulta ventajoso para aplicaciones con tipos de datos diversos o en rápida evolución, como las plataformas de redes sociales.
- Escalabilidad horizontal: Las bases de datos NoSQL están diseñadas para el escalado horizontal, que distribuye los datos entre varios servidores. Esto las hace muy eficientes para gestionar grandes conjuntos de datos y altas cargas de tráfico, proporcionando una solución rentable para escalar aplicaciones.
- Alto rendimiento para consultas sencillas: Las bases de datos no relacionales sobresalen en la recuperación rápida de datos para consultas sencillas, lo que las hace ideales para el almacenamiento en caché, el procesamiento de datos en tiempo real y las aplicaciones que priorizan la velocidad sobre las consultas complejas.
Contras:
- Capacidades de consulta limitadas: Aunque las bases de datos NoSQL admiten varios modelos de datos, a menudo carecen de las complejas capacidades de consulta de SQL, lo que las hace menos adecuadas para aplicaciones que requieren uniones y relaciones de datos intrincadas.
- Menos consistencia: Muchas bases de datos NoSQL priorizan la disponibilidad y la tolerancia a las particiones sobre la estricta consistencia de los datos, lo que puede no cumplir los estándares de las aplicaciones que exigen el cumplimiento de ACID.
- Ecosistema menos maduro: Las bases de datos no relacionales son más recientes que las relacionales, por lo que su conjunto de herramientas y el apoyo de la comunidad están menos consolidados. Esto puede plantear problemas de mantenimiento a largo plazo y de integración con otros sistemas.
Las bases de datos relacionales son ideales para aplicaciones que requieren una gran coherencia de datos, consultas complejas y fiabilidad. Las bases de datos no relacionales, en cambio, ofrecen mayor flexibilidad y escalabilidad, por lo que son adecuadas para entornos dinámicos y de gran volumen de datos. En última instancia, la elección depende de la naturaleza de los datos, los requisitos de la aplicación y las necesidades de escalabilidad.
Base de datos relacional frente a no relacional
Para resumir la diferencia entre bases de datos relacionales y no relacionales: las bases de datos relacionales almacenan los datos en filas y columnas como una hoja de cálculo, mientras que las bases de datos no relacionales no lo hacen. En cambio, las bases de datos no relacionales utilizan uno de los cuatro modelos de almacenamiento -basado en documentos, clave-valor, columna-familia o gráfico- que mejor se adaptan al tipo de datos almacenados.
Las bases de datos relacionales son ideales para aplicaciones que requieren datos estructurados con un alto nivel de integridad y soporte para consultas SQL complejas. Destacan en situaciones que requieren una coherencia estricta de los datos, ya que los organizan mediante un esquema predefinido. Las bases de datos no relacionales, por su parte, ofrecen flexibilidad para datos no estructurados o en evolución y escalan horizontalmente a través de sistemas distribuidos. Son idóneas para manejar conjuntos de datos grandes, diversos o dinámicos en los que el desarrollo rápido y la escalabilidad son prioridades clave.
Preguntas que hay que plantearse antes de elegir una base de datos
¿Qué tipo de datos va a analizar?
¿Sus datos caben cómodamente en filas y columnas? ¿O se adaptan mejor a un espacio más flexible? La respuesta le dirá si necesita una base de datos relacional o no relacional.
¿Cuántos datos maneja?
Una buena regla general es la siguiente: cuanto mayor sea el conjunto de datos, más probable es que una base de datos no relacional sea la más adecuada. Las bases de datos no relacionales pueden almacenar conjuntos ilimitados de datos de cualquier tipo y tienen la flexibilidad de cambiar el tipo de datos.
Pero las bases de datos relacionales funcionan mejor cuando se realizan operaciones intensivas de lectura y escritura en conjuntos de datos de tamaño pequeño o mediano.
¿Qué tipo de recursos puede dedicar a la configuración y mantenimiento de su base de datos?
He aquí otra buena regla empírica: cuanto más pequeño sea su equipo de ingenieros, más probable es que una base de datos relacional sea la más adecuada. ¿Por qué? En primer lugar, las bases de datos relacionales requieren menos tiempo de gestión. Además, SQL es un lenguaje de consulta más conocido. Es más probable que su equipo ya lo conozca.
Las bases de datos no relacionales pueden requerir más conocimientos de programación, lo que significa que su equipo tendrá que aprender otros tipos de lenguajes de consulta. O tendrás que contratar a alguien con más conocimientos de código.
¿Necesita datos en tiempo real?
El análisis en tiempo real está en boca de todos. No se puede subestimar la ventaja competitiva que aporta y su impacto en la toma de decisiones. Sin embargo, es importante señalar que no todas las organizaciones necesitan datos en tiempo real. Puede que sus datos no cambien mucho. Tal vez le interese más analizar conjuntos de datos pasados. En ese caso, las bases de datos relacionales funcionan bien.
Logi Symphony: Aproveche toda su nube en informes y cuadros de mando
Logi Symphony es un producto/paquete de insightsoftware diseñado específicamente para integrarse en su aplicación y ofrecer análisis e informes de autoservicio a sus usuarios finales. Logi Symphony permite a los usuarios simples y avanzados por igual crear informes sólidos y descubrir información procesable para tomar mejores decisiones empresariales.
Los gestores de productos aumentan su oferta de productos con Logi Symphony para conectarse a prácticamente cualquier fuente de datos directamente o aprovechando las API REST. Además, Logi Symphony contiene una capa de datos ETL-lite que proporciona numerosas funciones para resolver los problemas relacionados con los datos que pueda experimentar con sus necesidades integradas de Reporting y BI. Con la capa de datos de Logi Symphony, puede:
- Aumente y optimice el rendimiento de los datos con cubos en memoria patentados.
- Aumente el rendimiento y la fiabilidad de los datos con el almacenamiento de datos integrado y la indexación automática de datos.
- Aumente y amplíe los datos para mejorar el análisis utilizando transformaciones integradas para resolver los problemas habituales de los datos.
- Habilite análisis predictivos, IA y aprendizaje automático o reglas de datos personalizadas sobre sus datos aprovechando lenguajes de programación como C#, Python o R.
- Cree una experiencia de usuario personalizada protegiendo los datos por usuario con seguridad a nivel de fila/columna.