Was ist der Unterschied? Relationale vs. nicht-relationale Datenbanken
Was ist der Unterschied zwischen relationalen und nicht-relationalen Datenbanken? Ein relationales Datenbankmanagementsystem (RDBMS) organisiert Daten in separaten Tabellen und ermöglicht so einen flexiblen Zugriff und die Wiederzusammensetzung nach benutzerdefinierten relationalen Tabellen. Im Gegensatz dazu verwendet eine nicht-relationale Datenbank eine Architektur, die sich nicht auf Tabellen als primäre Struktur stützt.
Stellen Sie sich vor, Ihre Daten seien ein Hund. Vor ihm platzieren Sie eine Excel-Tabelle und ein Word-Dokument. Zu welchem wird der Hund gehen?
Es mag ein wenig albern sein - aber es ist ein guter Weg, um genau zu verstehen, welche Art von Daten für die beiden Haupttypen von Datenbanken - relationale und nicht-relationale - geeignet sind. Lassen Sie uns den Unterschied zwischen relationalen Datenbanken und nicht-relationalen Datenbanksystemen erläutern - und einige wichtige Fragen auflisten, die jedes Unternehmen beantworten sollte, bevor es sich für eine relationale Datenbank oder eine nicht-relationale Datenbank entscheidet.
Relationale vs. nicht-relationale Datenbanken
Der Unterschied zwischen relationalen und nicht-relationalen Datenbanken spiegelt die grundlegenden Unterscheidungen bei Datenverwaltungssystemen wider. Relationale Datenbanken organisieren Daten in miteinander verknüpften Tabellen, verwenden ein strukturiertes Format, das Zeilen und Spalten innerhalb eines Schemas definiert, und verwenden SQL (Structured Query Language) für strukturierte Abfragen. Dieser Aufbau ist ideal für stark strukturierte Datenanforderungen, bei denen Datenintegrität und komplexe Abfragemöglichkeiten wichtig sind. Relationale Datenbanken eignen sich hervorragend für die Verarbeitung strukturierter Daten und gewährleisten durch vordefinierte Beziehungen zwischen den Tabellen die Konsistenz und Genauigkeit der Dateneinträge. Daher eignen sie sich gut für Anwendungen in Bereichen wie Finanzen, Gesundheitswesen und ERP-Systeme, wo Datengenauigkeit, Konsistenz und Unterstützung für komplizierte Verknüpfungsoperationen erforderlich sind.
Auf der anderen Seite bieten nicht-relationale Datenbanken oder NoSQL-Datenbanken flexible Speicherlösungen, die verschiedene Datentypen wie Dokumente, Schlüssel-Wert-Paare, spaltenbasierte Speicher und Graphstrukturen aufnehmen können. Diese Flexibilität ist von Vorteil, wenn es um unstrukturierte oder halbstrukturierte Daten geht, die nicht genau in ein starres Schema passen. NoSQL-Datenbanken sind für skalierbare Anwendungen ausgelegt und unterstützen verteilte Cluster, so dass sie große Datenmengen und hohe Verkehrslasten bewältigen können. Diese Skalierbarkeit und Anpassungsfähigkeit machen nicht-relationale Datenbanken zur idealen Wahl für Anwendungen, die eine schnelle Entwicklung erfordern und von einem schemafreien Design profitieren können, wie z. B. Social-Media-Plattformen, IoT-Netzwerke und Content-Management-Systeme.
Die Wahl zwischen relationalen und nicht-relationalen Datenbanken hängt letztlich davon ab, ob strukturierte Datenintegrität und komplexe Abfragen oder Skalierbarkeit und Flexibilität bei der Datenverarbeitung gefragt sind. Relationale Datenbanken eignen sich am besten für Anwendungsfälle, in denen Datenstruktur und -integrität entscheidend sind, während nicht-relationale Datenbanken sich in Umgebungen auszeichnen, in denen Flexibilität, schnelle Skalierbarkeit und der Umgang mit unterschiedlichen Datentypen wichtiger sind.
Was sind relationale Datenbanken?
Kehren wir zu Ihrem "Datenhund" zurück. Vielleicht bevorzugt er die Excel-Tabelle. Und warum? Weil es gut in die Zeilen und Spalten passt.
In einer relationalen Datenbank werden Daten in Tabellen gespeichert. Die Beziehung zwischen den einzelnen Datenpunkten ist klar und die Suche nach diesen Beziehungen ist relativ einfach. Die Beziehung zwischen Tabellen und Feldtypen wird als Schema bezeichnet. Bei relationalen Datenbanken muss das Schema klar definiert sein. Aus der Sicht einer relationalen Datenbank ist sie ein integraler Bestandteil der dreistufigen Architektur und spielt eine zentrale Rolle bei der Gewährleistung von Datenintegrität, Sicherheit und effizienter Datenverwaltung innerhalb der Datenschicht der Anwendung.
Relationale Datenbanken eignen sich besonders gut für die Verwaltung strukturierter Daten, bei denen die Daten in vordefinierte Felder und Zeilen passen müssen. Durch ihre Abhängigkeit von Schemata erzwingen relationale Datenbanken eine strikte Datenkonsistenz, die dazu beiträgt, dass alle Dateneinträge einem bestimmten Format entsprechen und die Integrität erhalten bleibt. Aufgrund dieser Struktur eignen sich relationale Datenbanken hervorragend für Branchen, in denen Genauigkeit und Zuverlässigkeit gefragt sind, z. B. im Finanzwesen, im Gesundheitswesen und in der Logistik, wo die Datenvalidierung für den täglichen Betrieb von entscheidender Bedeutung ist.
Eine der größten Stärken relationaler Datenbanken ist ihre Unterstützung für komplexe Abfragen und Verknüpfungen. SQL bietet leistungsstarke Abfragefunktionen, mit denen Daten aus mehreren Tabellen auf der Grundlage spezifischer Beziehungen abgerufen und kombiniert werden können, was tiefgreifende Analysen und Berichte ermöglicht. Diese Fähigkeit ist besonders nützlich in Customer Relationship Management (CRM) und Enterprise Resource Planning (ERP)-Systemen, wo oft Daten aus verschiedenen Bereichen zusammengeführt werden müssen, um ein vollständiges Bild zu erhalten.
Relationale Datenbanken unterstützen auch ACID-Eigenschaften (Atomicity, Consistency, Isolation, Durability), die für die Aufrechterhaltung zuverlässiger Transaktionen unerlässlich sind. Diese Eigenschaften verhindern partielle Aktualisierungen und stellen sicher, dass entweder alle Teile einer Transaktion abgeschlossen werden oder gar keine, was relationale Datenbanken ideal für kritische Anwendungen macht, bei denen die Datengenauigkeit nicht verhandelbar ist.
Insgesamt macht der strukturierte, schema-basierte Ansatz relationaler Datenbanken in Verbindung mit ihren robusten Abfrage- und Transaktionsfunktionen sie zu einem grundlegenden Werkzeug für Anwendungen, die auf Datenintegrität, konsistente Struktur und komplexe Analysen angewiesen sind.
Schauen wir uns ein Beispiel an:
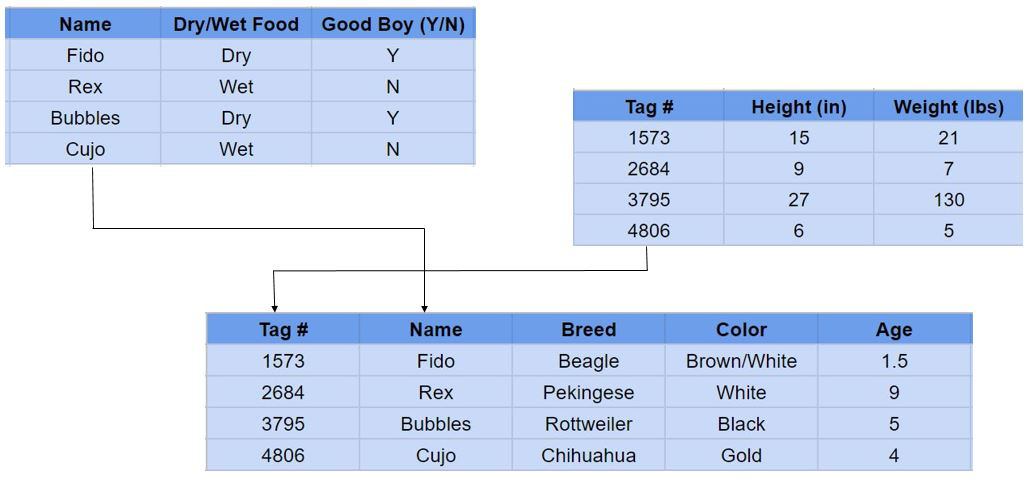
Hier sehen wir drei Tabellen, die alle eindeutige Informationen über einen bestimmten Hund enthalten. Ein Benutzer einer relationalen Datenbank kann dann eine Ansicht der Datenbank erhalten, die seinen Bedürfnissen entspricht. Zum Beispiel könnte ich alle Hunde über 100 Pfund anzeigen oder einen Bericht darüber erstellen wollen. Oder Sie möchten sehen, welche Rassen Trockenfutter fressen. Relationale Datenbanken machen die Beantwortung von Fragen wie diesen relativ einfach.
Relationale Datenbanken werden auch SQL-Datenbanken genannt. SQL steht für Structured Query Language und ist die Sprache, in der relationale Datenbanken geschrieben sind. SQL wird verwendet, um Abfragen auszuführen, Daten abzurufen und Daten durch Aktualisieren, Löschen oder Erstellen neuer Datensätze zu bearbeiten.
Die frühe Einführung und weite Verbreitung machen SQL-Datenbanken zu einem beliebten Datenverwaltungssystem. Dies ist zum Teil darauf zurückzuführen, dass die Mitarbeiter nicht geschult werden müssen, da viele Datenwissenschaftler SQL schon früh erlernen. Schauen wir uns die Unterschiede zwischen relationalen und nicht-relationalen Datenbanken genauer an.
Beispiele für beliebte relationale/SQL-Datenbanken
SQL-Server
![]()
SQL Server ist ein von Microsoft entwickeltes relationales Datenbankmanagementsystem. Relationale Datenbankmanagementsysteme bieten mehrere Editionen mit unterschiedlichen Funktionen für verschiedene Benutzer.
Vorteile: SQL Server verfügt über eine umfangreiche Benutzeroberfläche und kann große Datenmengen verarbeiten.
Nachteile: Es kann teuer sein - die Enterprise-Ebene kostet Tausende von Dollar.
MySQL
![]()
Erstmals veröffentlicht im Jahr 1995, MySQL ist eine freie und quelloffene Software und eine der beliebtesten Datenbanken der Welt. Sie wird von vielen stark frequentierten Websites wie Facebook und YouTube verwendet.
Vorteile: Es ist kostenlos und Open-Source. Außerdem gibt es eine umfangreiche Dokumentation und Online-Support.
Nachteile: Es ist nicht sehr gut skalierbar. MySQL neigt dazu, nicht mehr zu funktionieren, wenn zu viele Operationen auf einmal ausgeführt werden.
PostgreSQL
![]()
MySQL basiert auf dem relationalen Modell, PostgreSQL basiert auf dem objekt-relationalen Modell. PostgreSQL, eine weitere freie und quelloffene Datenbank, wurde 1996 mit dem Schwerpunkt auf Erweiterbarkeit veröffentlicht. Dank seiner vielfältigen Erweiterungsfunktionen ist es in der Lage, komplizierte Datenmengen zu verarbeiten.
Vorteile: Wie schon gesagt, erweiterbar. Wenn Sie zusätzliche Funktionen in PostgreSQL benötigen, können Sie diese selbst hinzufügen - eine schwierige Aufgabe bei den meisten Datenbanken.
Nachteile: Für Anfänger kann die Installation und Konfiguration schwierig sein. Es gibt auch nicht annähernd so viel Dokumentation wie bei populäreren Datenbanken wie MySQL.
Was sind nicht-relationale Datenbanken?
Zurück zu Ihrem "Datenhund". Diesmal ging er zum Word-Dokument über. Und warum? Der ganze freie Platz! Die Daten kommen in allen möglichen Formen und Größen - sie brauchen Platz, um sich auszubreiten.
Eine nicht-relationale Datenbank ist eine Datenbank, die nicht das tabellarische Schema von Zeilen und Spalten wie in relationalen Datenbanken verwendet. Stattdessen ist ihr Speichermodell für die Art der gespeicherten Daten optimiert und ermöglicht die Speicherung von Daten in verschiedenen Formaten wie Dokumenten, Schlüssel-Wert-Paaren, Diagrammen oder Spalten. Durch diese Flexibilität in der Struktur sind nicht-relationale Datenbanken ideal für Anwendungen mit sich entwickelnden oder unstrukturierten Daten, die sich nicht in vordefinierte Kategorien einordnen lassen.

Nicht-relationale Datenbanken werden auch als NoSQL-Datenbanken bezeichnet, was für "Not Only SQL" steht. Während relationale Datenbanken für die Datenverwaltung ausschließlich auf SQL zurückgreifen, können nicht-relationale Datenbanken eine Vielzahl anderer Abfragesprachen verwenden, die oft spezifisch für ihr Datenmodell sind. Dank dieser Mehrsprachigkeit können NoSQL-Datenbanken Daten auf eine Weise verarbeiten, die auf verschiedene Speichertypen zugeschnitten ist, und so die Leistung und Skalierbarkeit für bestimmte Anwendungsfälle verbessern.
Es gibt vier verschiedene Arten von NoSQL-Datenbanken:
Nicht-relationale Datenbanken sind besonders wertvoll, wenn es um große, komplexe oder sich schnell ändernde Daten geht. Sie unterstützen verschiedene Datenmodelle, wie z. B.:
1. Dokumentenbasierte Datenbanken
- Diese Datenbanken, wie MongoDB und CouchDB, speichern Daten als Dokumente (oft im JSON- oder BSON-Format), was die Verwaltung komplexer, hierarchischer Daten in einem einzigen Datensatz erleichtert. Dieses Modell ist besonders nützlich für Content-Management-Systeme, bei denen jedes Dokument einzigartige Strukturen und Felder haben kann.
2. Schlüssel-Wert-Speicher
- Datenbanken wie Redis und DynamoDB verwenden ein einfaches Modell, bei dem jedes Element als Schlüssel-Wert-Paar gespeichert wird, was einen schnellen Datenabruf ermöglicht. Schlüsselwertspeicher sind aufgrund ihres schnellen Zugriffs ideal für das Caching und die Sitzungsverwaltung.
3. Geschäfte mit Säulenfamilien
- Datenbanken wie Cassandra und HBase speichern Daten eher spalten- als zeilenweise, was sie effizient für die Verarbeitung großer Mengen strukturierter Daten in verteilten Systemen macht. Dieses Modell ist bei Datenanalyseanwendungen üblich, bei denen Operationen häufig auf Spalten und nicht auf Zeilen ausgeführt werden.
4. Graphische Datenbanken
- Datenbanken wie Neo4j und Amazon Neptune konzentrieren sich auf die Beziehungen zwischen Datenpunkten, was besonders bei sozialen Netzwerken, Empfehlungsmaschinen und der Betrugserkennung nützlich ist. Durch die Modellierung von Entitäten als Knoten und Beziehungen als Kanten ermöglichen Graphdatenbanken die effiziente Verwaltung und Abfrage komplexer, miteinander verbundener Daten.
Nicht-relationale Datenbanken sind auch auf Skalierbarkeit und Flexibilität ausgelegt. Im Gegensatz zu herkömmlichen Datenbanken, die oft eine vertikale Skalierung (Hinzufügen von mehr Leistung zu einem einzelnen Server) erfordern, ermöglichen NoSQL-Datenbanken in der Regel eine horizontale Skalierung durch die Verteilung von Daten auf mehrere Server. Dieser verteilte Ansatz ermöglicht es Anwendungen, große Datenmengen und hohe Verkehrslasten zu bewältigen, und bietet eine kosteneffektive Möglichkeit zur Skalierung bei wachsenden Datenanforderungen. Diese Eigenschaft macht nicht-relationale Datenbanken zur bevorzugten Wahl für Cloud-native Anwendungen, Echtzeit-Analysen und Big-Data-Umgebungen.
NoSQL-Datenbanken bieten auch eine hohe Anpassungsfähigkeit für eine agile Entwicklung. In Anwendungen, in denen sich Datenmodelle häufig ändern oder neue Datentypen schnell integriert werden müssen, bieten nicht-relationale Datenbanken ein schemafreies Design, das die Entwicklung vereinfacht. Diese Flexibilität ermöglicht es Teams, Anpassungen ohne Ausfallzeiten oder komplexe Migrationen vorzunehmen, was NoSQL-Datenbanken zu einer attraktiven Option für Startups, MVPs (Minimum Viable Products) und Projekte macht, bei denen schnelle Iterationen wichtig sind.
Insgesamt bieten nicht-relationale Datenbanken eine leistungsstarke, skalierbare und flexible Lösung für Anwendungen, die verschiedene Datentypen, Daten mit hoher Geschwindigkeit und komplexe Beziehungen verwalten. Ihre Fähigkeit, unstrukturierte Daten effizient zu verarbeiten und problemlos zu skalieren, macht sie zu einer grundlegenden Technologie für moderne, datengesteuerte Anwendungen.
Beispiele für beliebte nicht-relationale/NoSQL-Datenbanken
MongoDB
![]()
MongoDB ist ein Dokumentenspeicher und derzeit die beliebteste NoSQL-Datenbank-Engine, die verwendet wird. Sie verwendet JSON-ähnliche Dokumente zum Speichern von Daten und wird über mehrere Server ausgeführt. MongoDB ermöglicht Auto-Sharding, eine Art der Datenbankpartitionierung, bei der sehr große Datenbanken in kleinere, schnellere und leichter zu verwaltende Teile, so genannte Data Shards, aufgeteilt werden.
Vorteile: MongoDB ist sehr einfach einzurichten und bietet eine Menge professionellen Support.
Nachteile: Sie erlauben keine Joins. Joins werden verwendet, um Daten oder Zeilen aus zwei oder mehr Tabellen auf der Grundlage eines gemeinsamen Feldes zwischen ihnen zu kombinieren. MongoDB verfügt zwar über eine LOOKUP-Funktion, weist seine Benutzer aber an, sich nicht auf sie zu verlassen.
Redis
![]()
Redis - Remote Dictionary Server - ist ein Key-Value-Speicher. Er unterstützt verschiedene Arten von abstrakten Datenstrukturen wie Strings, Listen, Maps, Sets, sortierte Sets und mehr. Es ist auch Open-Source.
Vorteile: Es unterstützt eine große Anzahl von Datentypen und ist einfach zu installieren.
Nachteile: Wie MongoDB unterstützt es keine Joins. Außerdem erfordert es Kenntnisse in Lua, einer Programmiersprache auf hoher Ebene.
Wann sollte man relationale und wann nicht-relationale Datenbanken verwenden?
Bei der Entscheidung zwischen relationalen und nicht-relationalen Datenbanken für Ihr Projekt ist es wichtig, die spezifischen Anforderungen und Merkmale Ihrer Daten zu berücksichtigen sowie die Art und Weise, wie Sie sie nutzen wollen. Im Folgenden wird detailliert untersucht, in welchen Situationen die eine der anderen vorzuziehen ist:
Wann sollte man relationale Datenbanken verwenden?
Relationale Datenbanken sind eine gute Wahl für die Datenverwaltung, wenn ein hohes Maß an Struktur, Konsistenz und Datenintegrität erforderlich ist. Mit einem klar definierten Schema und strengen Datenbeziehungen eignen sich relationale Datenbanken hervorragend für Anwendungen, bei denen Datengenauigkeit und anspruchsvolle Abfragen von größter Bedeutung sind.
Anforderungen an strukturierte Daten
Relationale Datenbanken sind die bevorzugte Option, wenn es um stark strukturierte Daten geht, die einem einheitlichen Format folgen. In Szenarien, in denen alle Daten sauber in vordefinierte Zeilen und Spalten passen, ermöglichen relationale Datenbanken eine präzise Organisation und Validierung der Dateneingabe. Diese Struktur ist ideal für Unternehmensanwendungen, transaktionale Systeme und jede Umgebung, in der ein detailliertes Schema im Voraus festgelegt werden kann. Relationale Datenbanken erzwingen die Datenintegrität durch Schemaregeln, die sicherstellen, dass die Daten in allen Tabellen konsistent und organisiert bleiben.
Komplexe Abfragen und Join-Operationen
Relationale Datenbanken sind für komplexe Abfragen ausgelegt, die sich über mehrere Tabellen erstrecken und erweiterte Verknüpfungsoperationen erfordern. Wenn Anwendungen Daten über verschiedene Tabellen hinweg mit präzisen Bedingungen abrufen müssen, bieten relationale Datenbanken robuste Unterstützung durch Structured Query Language (SQL). In Systemen wie Plattformen für das Kundenbeziehungsmanagement (CRM) oder die Finanzberichterstattung, in denen Daten miteinander verbunden sind und oft auf komplizierte Weise abgefragt werden, ermöglichen relationale Datenbanken eine effiziente und genaue Abfrageausführung.
ACID-Transaktionen
Relationale Datenbanken unterstützen ACID-Transaktionen (Atomicity, Consistency, Isolation, Durability), eine Reihe von Eigenschaften, die eine zuverlässige Datenverarbeitung in mehrstufigen Prozessen gewährleisten. Diese Eigenschaften sind für Anwendungen in Bereichen wie dem Finanzwesen, dem Bankwesen und dem elektronischen Handel unerlässlich, wo ein hohes Maß an Datengenauigkeit und -konsistenz entscheidend ist. Durch die Unterstützung von ACID-Transaktionen behalten relationale Datenbanken die Datenintegrität auch bei Systemfehlern oder -abstürzen bei und eignen sich daher für unternehmenskritische Anwendungen, bei denen die Datengenauigkeit nicht verhandelbar ist.
Ausgereifte Tools und Ökosystem
Aufgrund ihrer jahrzehntelangen Entwicklung verfügen relationale Datenbanken über ein gut etabliertes Ökosystem von Tools, Support und Ressourcen. Dieser Reifegrad bietet umfangreiche Lösungen für Datensicherung, Überwachung und Leistungsoptimierung. Tools wie Oracle Database, MySQL und Microsoft SQL Server verfügen über einen soliden Community- und kommerziellen Support, der eine einfache Integration mit Analyseplattformen, Business Intelligence-Tools und ETL-Prozessen (Extract, Transform, Load) ermöglicht. Dieses etablierte Ökosystem vereinfacht den Betrieb und bietet Zuverlässigkeit für Unternehmensumgebungen, die stabile, langfristige Datenlösungen benötigen.
Wann man nicht-relationale Datenbanken verwenden sollte
Nicht-relationale Datenbanken oder NoSQL-Datenbanken bieten die Flexibilität und Skalierbarkeit, die für die Verwaltung unterschiedlicher und schnell wachsender Datensätze erforderlich sind. Sie sind so konzipiert, dass sie unterschiedliche Datenstrukturen verarbeiten können, was sie ideal für Anwendungen mit schnellen Entwicklungsanforderungen und umfangreichen Datenanforderungen macht.
Flexible Datenmodelle
Nicht-relationale Datenbanken eignen sich gut für den Umgang mit unstrukturierten oder halbstrukturierten Daten und bieten die Flexibilität, die relationalen Datenbanken fehlt. Sie benötigen kein starres Schema, sodass sich die Datenstrukturen im Laufe der Zeit weiterentwickeln können, ohne dass die Datenbankstruktur geändert werden muss. Dies macht NoSQL-Datenbanken zu einer ausgezeichneten Wahl für Anwendungen mit unterschiedlichen Datenquellen, wie z. B. Social-Media-Plattformen, bei denen sich die Datenformate aufgrund neuer Funktionen oder nutzergenerierter Inhalte ändern und anpassen können.
Skalierbarkeit
NoSQL-Datenbanken sind für eine horizontale Skalierung ausgelegt, d. h. sie können Daten über mehrere Server oder Cluster verteilen. Dadurch eignen sie sich hervorragend für Anwendungen, die mit großen Datenmengen und hohem Datenverkehr rechnen, wie z. B. groß angelegte Webanwendungen oder IoT-Plattformen. Durch die Nutzung verteilter Systeme ermöglichen nicht-relationale Datenbanken eine kostengünstige Skalierung ohne die Einschränkungen herkömmlicher, vertikal skalierter relationaler Datenbanken. Diese Skalierbarkeit ist für Unternehmen von Vorteil, die ein schnelles Wachstum erwarten oder mit Big-Data-Szenarien arbeiten.
Hohe Leistung mit einfachen Abfragen
Für Anwendungen mit einfachen Abfragemustern und hohen Leistungsanforderungen sind nicht-relationale Datenbanken eine optimale Lösung. In Fällen wie Caching, Sitzungsmanagement oder Inhaltsbereitstellung bieten NoSQL-Datenbanken wie Key-Value-Stores und Dokumentendatenbanken schnelle Lese- und Schreibfunktionen. Diese Geschwindigkeit ist besonders nützlich für Echtzeitanwendungen, bei denen die Latenzzeit minimal sein muss und ein einfacher, direkter Datenabruf im Vordergrund steht.
Schnelle Entwicklung
Die schemafreie Struktur von NoSQL-Datenbanken unterstützt schnelle Iterationen und ist daher ideal für Projekte, bei denen sich das Datenmodell im Laufe der Zeit weiterentwickelt. In agilen Entwicklungsumgebungen, in denen häufig neue Funktionen hinzugefügt werden und sich die Datenanforderungen ändern, ermöglichen nicht-relationale Datenbanken den Entwicklern eine schnelle Anpassung der Datenstrukturen ohne die Beschränkungen eines starren Schemas. Diese Flexibilität macht NoSQL-Datenbanken zu einer attraktiven Wahl für Startups, MVPs (Minimum Viable Products) und andere Anwendungen mit sich verändernden Datenanforderungen.
Nicht-relationale Datenbanken bieten die Flexibilität und Leistung, die moderne, datenintensive Anwendungen erfordern, und sind daher für eine dynamische Skalierung und Anpassung an sich ändernde Anforderungen unerlässlich.
Relationale vs. nicht-relationale Datenbank: Pro und Kontra
Bei der Entscheidung zwischen relationalen und nicht-relationalen Datenbanken ist es wichtig, die Stärken und Grenzen der einzelnen Typen zu kennen. Beide Datenbanktypen bieten einzigartige Vorteile, so dass die beste Wahl von den spezifischen Anforderungen der Anwendung und den Bedürfnissen der Datenverarbeitung abhängt.
Relationale Datenbank Pro und Kontra
Vorteile:
- Datenintegrität und -konsistenz: Relationale Datenbanken erzwingen Datengenauigkeit durch strenge Schemata und ACID-Konformität, was sie ideal für Anwendungen macht, bei denen Datenintegrität entscheidend ist, z. B. im Finanz- und Gesundheitswesen.
- Komplexe Abfragefähigkeiten: SQL ermöglicht leistungsstarke Abfragen und Verknüpfungen über mehrere Tabellen hinweg, was detaillierte Analysen und komplexe Datenabfragen ermöglicht. Dadurch eignen sich relationale Datenbanken gut für Berichte und analytische Aufgaben.
- Ausgereiftes Ökosystem: Relationale Datenbanken blicken auf eine lange Geschichte zurück, die zu einer soliden Unterstützung, Tools und Ressourcen für Backup, Überwachung und Optimierung geführt hat, was sie in Unternehmensumgebungen äußerst zuverlässig macht.
Nachteile:
- Starres Schema: Relationale Datenbanken erfordern ein vordefiniertes Schema, was die Anpassung an sich ändernde Datenanforderungen oder die Aufnahme unstrukturierter Daten erschweren kann.
- Einschränkungen bei der Skalierbarkeit: Die meisten relationalen Datenbanken beruhen auf vertikaler Skalierung (Hinzufügen von mehr Leistung zu einem einzelnen Server), was bei umfangreichen Anwendungen kostspielig und weniger effizient werden kann.
- Leistung bei großen Datenmengen: Relationale Datenbanken können bei der Bewältigung großer Datenmengen oder hoher Schreibgeschwindigkeiten Leistungsengpässe aufweisen, wodurch sie für Echtzeitanalysen oder Big-Data-Umgebungen weniger geeignet sind.
Nicht-relationale Datenbank Pro und Kontra
Vorteile:
- Flexibilität in der Datenstruktur: Nicht-relationale Datenbanken verwenden schemafreie Designs, die eine flexiblere und anpassungsfähigere Datenspeicherung ermöglichen. Dies ist vorteilhaft für Anwendungen mit unterschiedlichen oder sich schnell entwickelnden Datentypen, wie z. B. Social-Media-Plattformen.
- Horizontale Skalierbarkeit: NoSQL-Datenbanken sind für eine horizontale Skalierung ausgelegt, bei der die Daten auf mehrere Server verteilt werden. Dadurch sind sie äußerst effizient bei der Verwaltung großer Datenmengen und hoher Verkehrslasten und bieten eine kostengünstige Lösung für die Skalierung von Anwendungen.
- Hohe Leistung für einfache Abfragen: Nicht-relationale Datenbanken zeichnen sich durch einen schnellen Datenabruf bei einfachen Abfragen aus und sind daher ideal für Caching, Echtzeit-Datenverarbeitung und Anwendungen, bei denen Geschwindigkeit wichtiger ist als komplexe Abfragen.
Nachteile:
- Begrenzte Abfragemöglichkeiten: NoSQL-Datenbanken unterstützen zwar verschiedene Datenmodelle, verfügen aber häufig nicht über die komplexen Abfragefunktionen von SQL, so dass sie für Anwendungen, die komplizierte Joins und Datenbeziehungen erfordern, weniger geeignet sind.
- Weniger Konsistenz: Viele NoSQL-Datenbanken räumen der Verfügbarkeit und Partitionstoleranz Vorrang vor der strikten Datenkonsistenz ein, was möglicherweise nicht den Standards von Anwendungen entspricht, die ACID-Konformität erfordern.
- Weniger ausgereiftes Ökosystem: Nicht-relationale Datenbanken sind neuer als relationale, so dass ihre Tools und die Unterstützung durch die Gemeinschaft weniger ausgereift sind. Dies kann eine Herausforderung für die langfristige Wartung und Integration mit anderen Systemen darstellen.
Relationale Datenbanken sind ideal für Anwendungen, die eine hohe Datenkonsistenz, komplexe Abfragen und Zuverlässigkeit erfordern. Nicht-relationale Datenbanken hingegen bieten mehr Flexibilität und Skalierbarkeit und eignen sich daher für dynamische Umgebungen mit hohem Datenaufkommen. Die Wahl hängt letztlich von der Art der Daten, den Anwendungsanforderungen und den Skalierungsanforderungen ab.
Relationale vs. nicht-relationale Datenbank
Um den Unterschied zwischen relationalen und nicht-relationalen Datenbanken zusammenzufassen: relationale Datenbanken speichern Daten in Zeilen und Spalten wie eine Tabellenkalkulation, während nicht-relationale Datenbanken dies nicht tun. Stattdessen verwenden nicht-relationale Datenbanken eines von vier Speichermodellen - dokumentenbasiert, Key-Value, spaltenbasiert oder grafisch -, das am besten zu der Art der gespeicherten Daten passt.
Relationale Datenbanken sind ideal für Anwendungen, die strukturierte Daten mit einem hohen Maß an Integrität und Unterstützung für komplexe SQL-Abfragen erfordern. Sie eignen sich hervorragend für Szenarien, die eine strikte Datenkonsistenz erfordern, da sie die Daten anhand eines vordefinierten Schemas organisieren. Nicht-relationale Datenbanken hingegen bieten Flexibilität für unstrukturierte oder sich entwickelnde Daten und lassen sich horizontal über verteilte Systeme skalieren. Sie eignen sich gut für den Umgang mit großen, vielfältigen oder dynamischen Datensätzen, bei denen eine schnelle Entwicklung und Skalierbarkeit im Vordergrund stehen.
Fragen, die vor der Auswahl einer Datenbank zu beantworten sind
Welche Art von Daten werden Sie analysieren?
Passen Ihre Daten bequem in Zeilen und Spalten? Oder sind sie in einem flexibleren Raum besser aufgehoben? An der Antwort können Sie erkennen, ob Sie eine relationale oder eine nicht-relationale Datenbank benötigen.
Mit wie vielen Daten haben Sie es zu tun?
Eine gute Faustregel lautet: Je größer der Datensatz, desto eher ist eine nicht-relationale Datenbank geeignet. Nicht-relationale Datenbanken können unbegrenzte Datensätze mit beliebigem Typ speichern und haben die Flexibilität, den Datentyp zu ändern.
Relationale Datenbanken eignen sich jedoch am besten für intensive Lese- und Schreibvorgänge auf kleinen oder mittelgroßen Datensätzen.
Welche Ressourcen können Sie für die Einrichtung und Pflege Ihrer Datenbank bereitstellen?
Und noch eine gute Faustregel: Je kleiner Ihr Entwicklungsteam ist, desto wahrscheinlicher ist eine relationale Datenbank die bessere Wahl. Und warum? Zum einen erfordert die Verwaltung relationaler Datenbanken weniger Zeit. Außerdem ist SQL eine bekanntere Abfragesprache. Es ist wahrscheinlicher, dass Ihr Team sie bereits beherrscht.
Nicht-relationale Datenbanken erfordern möglicherweise mehr Programmierkenntnisse - das heißt, Ihr Team muss möglicherweise andere Abfragesprachen erlernen. Oder Sie müssen jemanden einstellen, der über mehr Code-Kenntnisse verfügt.
Benötigen Sie Echtzeitdaten?
Echtzeit-Analytik ist in aller Munde. Der Wettbewerbsvorteil, den sie bringt, und ihre Auswirkungen auf die Entscheidungsfindung können nicht unterschätzt werden. Es ist jedoch wichtig zu wissen, dass nicht jedes Unternehmen Echtzeitdaten benötigt. Vielleicht ändern sich Ihre Daten nicht so häufig. Vielleicht sind Sie eher daran interessiert, vergangene Datensätze zu analysieren. In diesem Fall sind relationale Datenbanken gut geeignet.
Logi Symphony: Nutzen Sie Ihre gesamte Cloud für Berichte und Dashboards
Logi Symphony ist ein Produktangebot/Bundle von insightsoftware, das speziell dafür entwickelt wurde, in Ihre Anwendung eingebettet zu werden und Ihren Endbenutzern Self-Service-Analysen und -Berichte zu liefern. Mit Logi Symphony können sowohl einfache als auch Power-User robuste Berichte erstellen und umsetzbare Erkenntnisse für bessere Geschäftsentscheidungen gewinnen.
Produktmanager erweitern ihr Produktangebot mit Logi Symphony, um eine direkte Verbindung zu praktisch jeder Datenquelle herzustellen oder REST APIs zu nutzen. Darüber hinaus enthält Logi Symphony eine ETL-Lite-Datenschicht, die zahlreiche Funktionen bietet, um datenbezogene Probleme zu lösen, die bei Ihren eingebetteten Reporting- und BI-Anforderungen auftreten können. Mit der Logi Symphony Datenschicht können Sie:
- Steigern und optimieren Sie die Datenleistung mit patentierten In-Memory-Cubes.
- Erhöhen Sie die Leistung und die Zuverlässigkeit der Daten mit integriertem Data Warehousing und automatischer Datenindizierung.
- Ergänzen und erweitern Sie Daten für eine bessere Analyse mithilfe integrierter Transformationen, um gängige Datenprobleme zu lösen.
- Aktivieren Sie prädiktive Analysen, KI und maschinelles Lernen oder benutzerdefinierte Datenregeln auf der Grundlage Ihrer Daten, indem Sie Programmiersprachen wie C#, Python oder R verwenden.
- Schaffen Sie ein maßgeschneidertes Benutzererlebnis, indem Sie Daten auf Zeilen-/Spaltenebene nach Benutzern sichern.