Les meilleurs modèles et algorithmes d'analyse prédictive à connaître

Les modèles d'analyse prédictive sont créés pour évaluer les données passées, découvrir des modèles, analyser les tendances et exploiter ces informations pour prévoir les tendances futures.
Les outils d'analyse prédictive sont alimentés par plusieurs modèles et algorithmes différents qui peuvent être appliqués à un large éventail de cas d'utilisation. Il est essentiel de déterminer les techniques de modélisation prédictive qui conviennent le mieux à votre entreprise pour tirer le meilleur parti d'une solution d'analyse prédictive et d'exploiter les données pour prendre des décisions éclairées.
Prenons l'exemple d'un détaillant qui cherche à réduire le taux d'attrition de sa clientèle. Les modèles d'analyse prédictive utilisés par un hôpital pour prévoir le nombre de patients admis aux urgences dans les dix jours à venir ne lui conviendraient peut-être pas.
Que sont les modèles d'analyse prédictive ?
Modèles d'analyse prédictive exploitent les données passées pour prévoir les événements futursLes modèles d'analyse prédictive exploitent les données passées pour prévoir les événements futurs, ce qui permet aux entreprises de prendre des décisions proactives fondées sur des données. Ces types de modèles de données utilisent diverses techniques pour découvrir des modèles et des tendances cachésCes modèles de données utilisent diverses techniques pour découvrir des modèles et des tendances cachés, fournissant ainsi des informations précieuses pour la planification stratégique et l'efficacité opérationnelle.
Envie d'aller plus loin ? Notre ressource gratuite vous guidera dans tous les domaines, des concepts fondamentaux aux techniques de prévision avancées. Que vous débutiez ou que vous cherchiez à développer votre analyse prédictive, ce guide vous aidera.
Quelles sont les données d'entrée pour l'élaboration de modèles d'analyse prédictive ?
L'élaboration de modèles d'analyse prédictive implique plusieurs éléments clés :
- Données historiques
-
-
- Description: Données antérieures relatives à la cible de l'analyse.
- Exemples: Registres des ventes, données sur le comportement des clients, données de capteurs.
-
- Prétraitement des données
-
-
- Description: Nettoyage et préparation des données pour l'analyse.
- Étapes: Traitement des valeurs manquantes, normalisation des données, suppression des valeurs aberrantes.
-
- Ingénierie des fonctionnalités
-
-
- Description: Création de nouvelles variables qui aident le modèle à mieux comprendre les données.
- Exemples: Combinaison de caractéristiques existantes, création de termes d'interaction, extraction de caractéristiques de date et d'heure.
-
- Sélection de l'algorithme
-
-
- Description: Choisir l'algorithme d'apprentissage automatique approprié à la tâche.
- Exemples: Régression linéaire, arbres de décision, réseaux neuronaux.
-
- Modèle Données d'entraînement
-
-
- Description: L'ensemble de données utilisé pour entraîner le modèle prédictif.
- Étapes: Diviser les données en ensembles de formation et de test, en veillant à une représentation équilibrée.
-
- Mesures d'évaluation
-
-
- Description: Critères d'évaluation de la performance du modèle.
- Exemples: Précision, exactitude, rappel, score F1, erreur quadratique moyenne.
-
- Connaissance du domaine
-
- Description: Une expertise dans le domaine spécifique pour guider le développement du modèle.
- Exemples: Comprendre les processus d'entreprise, les normes industrielles et les réglementations pertinentes.
Ces données contribuent collectivement à l'élaboration de modèles d'analyse prédictive robustes et précis.
Types de modèles d'analyse prédictive
Les modèles d'analyse prédictive utilisent des données historiques, des algorithmes statistiques et des techniques d'apprentissage automatique pour prédire les résultats futurs.. Les types courants de modèles prédictifs comprennent la classification (catégorisation des données), le regroupement (regroupement de données similaires) et les modèles de séries chronologiques (analyse des données dans le temps) afin d'identifier des modèles, des tendances et des événements futurs potentiels.
1. Modèle de classification
Le modèle de classification est, d'une certaine manière, le plus simple des différents types de modèles d'analyse prédictive que nous allons aborder. Il classe les données dans des catégories en fonction de ce qu'il apprend des données historiques.
Les modèles de classification sont les plus adaptés pour répondre à des questions de type oui ou non, en fournissant une analyse générale qui permet d'orienter les actions décisives. Ces modèles peuvent répondre à des questions telles que
- Pour un détaillant, "Ce client est-il sur le point de se désabonner ?".
- Pour un organisme de prêt, il s'agit de savoir si le prêt sera approuvé ou si le demandeur est susceptible de ne pas rembourser.
- Pour un fournisseur de services bancaires en ligne, "S'agit-il d'une transaction frauduleuse ?".
L'étendue des possibilités offertes par le modèle de classification - et la facilité avec laquelle il peut être réentraîné avec de nouvelles données - signifie qu'il peut être appliqué à de nombreux secteurs d'activité différents.
2. Modèle de regroupement
Le modèle de regroupement trie les données en groupes intelligents distincts et imbriqués, sur la base d'attributs similaires. Si une entreprise de vente de chaussures en ligne cherche à mettre en œuvre des campagnes de marketing ciblées pour ses clients, elle pourrait passer en revue les centaines de milliers d'enregistrements pour créer une stratégie sur mesure pour chaque individu. Mais s'agit-il de l'utilisation la plus efficace du temps ? Probablement pas. En utilisant le modèle de clustering, elle peut rapidement séparer les clients en groupes similaires sur la base de caractéristiques communes et concevoir des stratégies pour chaque groupe à une plus grande échelle.
Parmi les autres cas d'utilisation de cette technique de modélisation prédictive, on peut citer le regroupement des demandeurs de prêt en "groupes intelligents" en fonction des caractéristiques du prêt, l'identification des zones d'une ville où le taux de criminalité est élevé et l'analyse comparative des données des clients SaaS en groupes afin d'identifier les schémas d'utilisation globaux.
3. Modèle de prévision
L'un des modèles d'analyse prédictive les plus utilisés, le modèle de prévision, traite de la prédiction des valeurs métriques, estimant les valeurs numériques des nouvelles données sur la base des enseignements tirés des données historiques.
Ce modèle peut être appliqué partout où des données numériques historiques sont disponibles. Les scénarios sont les suivants :
- Une société SaaS peut estimer le nombre de clients qu'elle est susceptible de convertir au cours d'une semaine donnée.
- Un centre d'appel peut prévoir le nombre d'appels d'assistance qu'il recevra par heure.
- Un magasin de chaussures peut calculer la quantité de stock qu'il doit conserver pour répondre à la demande au cours d'une période de vente donnée.
Le modèle de prévision tient également compte de plusieurs paramètres d'entrée. Si un restaurateur souhaite prévoir le nombre de clients qu'il est susceptible de recevoir au cours de la semaine suivante, le modèle prendra en compte des facteurs susceptibles d'influer sur ce nombre : Y a-t-il un événement à proximité ? Quelles sont les prévisions météorologiques ? Y a-t-il une maladie qui circule ?
4. Modèle des valeurs aberrantes
Le modèle des valeurs aberrantes est axé sur les entrées de données anormales au sein d'un ensemble de données. Il permet d'identifier les chiffres anormaux, seuls ou associés à d'autres nombres et catégories.
- Enregistrement d'un pic d'appels d'assistance, ce qui pourrait indiquer une défaillance du produit susceptible d'entraîner un rappel.
- Recherche de données anormales dans les transactions, ou dans les demandes d'indemnisation, afin d'identifier les fraudes
- Trouver des informations inhabituelles dans vos journaux NetOps et remarquer les signes d'un temps d'arrêt non planifié imminent
Le modèle des valeurs aberrantes est particulièrement utile pour l'analyse prédictive dans les domaines de la vente au détail et de la finance. Par exemple, lors de l'identification de transactions frauduleuses, le modèle peut évaluer non seulement le montant, mais aussi le lieu, l'heure, l'historique des achats et la nature de l'achat (par exemple, un achat de 1 000 dollars de produits électroniques n'est pas aussi susceptible d'être frauduleux qu'un achat du même montant de livres ou d'équipements collectifs).
5. Modèle de série temporelle
Le modèle de série temporelle comprend une séquence de points de données capturés, en utilisant le temps comme paramètre d'entrée. Il utilise les données de la dernière année pour développer une mesure numérique et prédit les données des trois à six semaines suivantes à l'aide de cette mesure. Les cas d'utilisation de ce modèle comprennent le nombre d'appels quotidiens reçus au cours des trois derniers mois, les ventes des 20 derniers trimestres ou le nombre de patients qui se sont présentés dans un hôpital donné au cours des six dernières semaines. Il s'agit d'un moyen efficace de comprendre l'évolution d'un indicateur particulier dans le temps, avec un niveau de précision supérieur à celui des simples moyennes. Elle prend également en compte les saisons de l'année ou les événements susceptibles d'avoir un impact sur l'indicateur.
Si le propriétaire d'un salon de coiffure souhaite prédire le nombre de personnes susceptibles de visiter son établissement, il peut se tourner vers la méthode rudimentaire qui consiste à calculer la moyenne du nombre total de visiteurs au cours des 90 derniers jours. Cependant, la croissance n'est pas toujours statique ou linéaire, et le modèle des séries temporelles permet de mieux modéliser la croissance exponentielle et de mieux aligner le modèle sur la tendance de l'entreprise. Il permet également d'établir des prévisions pour plusieurs projets ou plusieurs régions en même temps, au lieu d'un seul à la fois.

Vous souhaitez appliquer ces modèles d'analyse prédictive en temps réel ?
Avec Logi Symphonyvous pouvez intégrer la prévision, la classification et la détection d'anomalies directement dans vos tableaux de bord et vos applications, sans avoir besoin d'une équipe spécialisée dans la science des données.
Découvrez comment Logi Symphony prend en charge l'analyse prédictive.
Que sont les algorithmes prédictifs ?
Les algorithmes d'analyse prédictive sont méthodes informatiques utilisées pour analyser des données historiques et de faire des prédictions sur des événements futurs. Ces algorithmes, tels que la régression linéaire, les arbres de décision et les réseaux neuronaux, identifient des modèles et des relations dans les données pour prévoir les résultatsCes algorithmes, tels que la régression linéaire, les arbres de décision et les réseaux neuronaux, identifient des modèles et des relations dans les données pour prévoir les résultats, ce qui permet une prise de décision éclairée et une planification stratégique.
Quels sont les algorithmes d'apprentissage automatique utilisés pour la prédiction ?
Les algorithmes d'apprentissage automatique utilisés pour la prédiction analysent les données historiques pour prévoir les résultats futurs. Ces algorithmes, notamment la régression linéaire, les arbres de décision et les réseaux neuronaux, identifient des modèles et des relations dans les données, ce qui permet de faire des prédictions précises et de prendre des décisions en connaissance de cause.
8 types d'algorithmes d'analyse prédictive
Globalement, les algorithmes d'analyse prédictive peuvent être séparés en deux groupes : l'apprentissage automatique et l'apprentissage profond.
- L'apprentissage automatique concerne des données structurées que nous voyons dans un tableau. Les algorithmes utilisés à cet effet sont à la fois linéaires et non linéaires. Les algorithmes linéaires s'entraînent plus rapidement, tandis que les algorithmes non linéaires sont mieux optimisés pour les problèmes auxquels ils sont susceptibles d'être confrontés (qui sont souvent non linéaires).
- L'apprentissage en profondeur est un sous-ensemble de l'apprentissage automatique qui est plus populaire pour traiter l'audio, la vidéo, le texte et les images.
Dans le cadre de la modélisation prédictive par apprentissage automatique, plusieurs algorithmes différents peuvent être appliqués. Voici quelques-uns des algorithmes les plus courants utilisés pour alimenter les modèles d'analyse prédictive décrits ci-dessus.
1. Forêt aléatoire
Random Forest est peut-être l'outil le plus populaire algorithme de classification le plus populaire, capable à la fois de classifier et de régresser. Il peut classer avec précision de grands volumes de données.
Le nom "Random Forest" vient du fait que l'algorithme est une combinaison d'arbres de décision. Chaque arbre dépend des valeurs d'un vecteur aléatoire échantillonné indépendamment avec la même distribution pour tous les arbres de la "forêt". Chacun d'entre eux est cultivé dans la mesure du possible.
Les algorithmes d'analyse prédictive tentent d'obtenir l'erreur la plus faible possible en utilisant soit le "boosting", soit l'analyse prédictive, soit l'analyse prédictive.boosting"(une technique qui ajuste le poids d'une observation en fonction de la dernière classification) ou "bagging"(qui crée des sous-ensembles de données à partir d'échantillons d'entraînement, choisis au hasard avec remplacement).
La forêt aléatoire utilise le bagging. Si vous disposez d'un grand nombre d'échantillons de données, au lieu de vous entraîner avec tous les échantillons, vous pouvez prendre un sous-ensemble et vous entraîner sur celui-ci, puis prendre un autre sous-ensemble et vous entraîner sur celui-ci (le chevauchement est autorisé). Tout cela peut se faire en parallèle. Plusieurs échantillons sont prélevés sur vos données pour créer une moyenne.
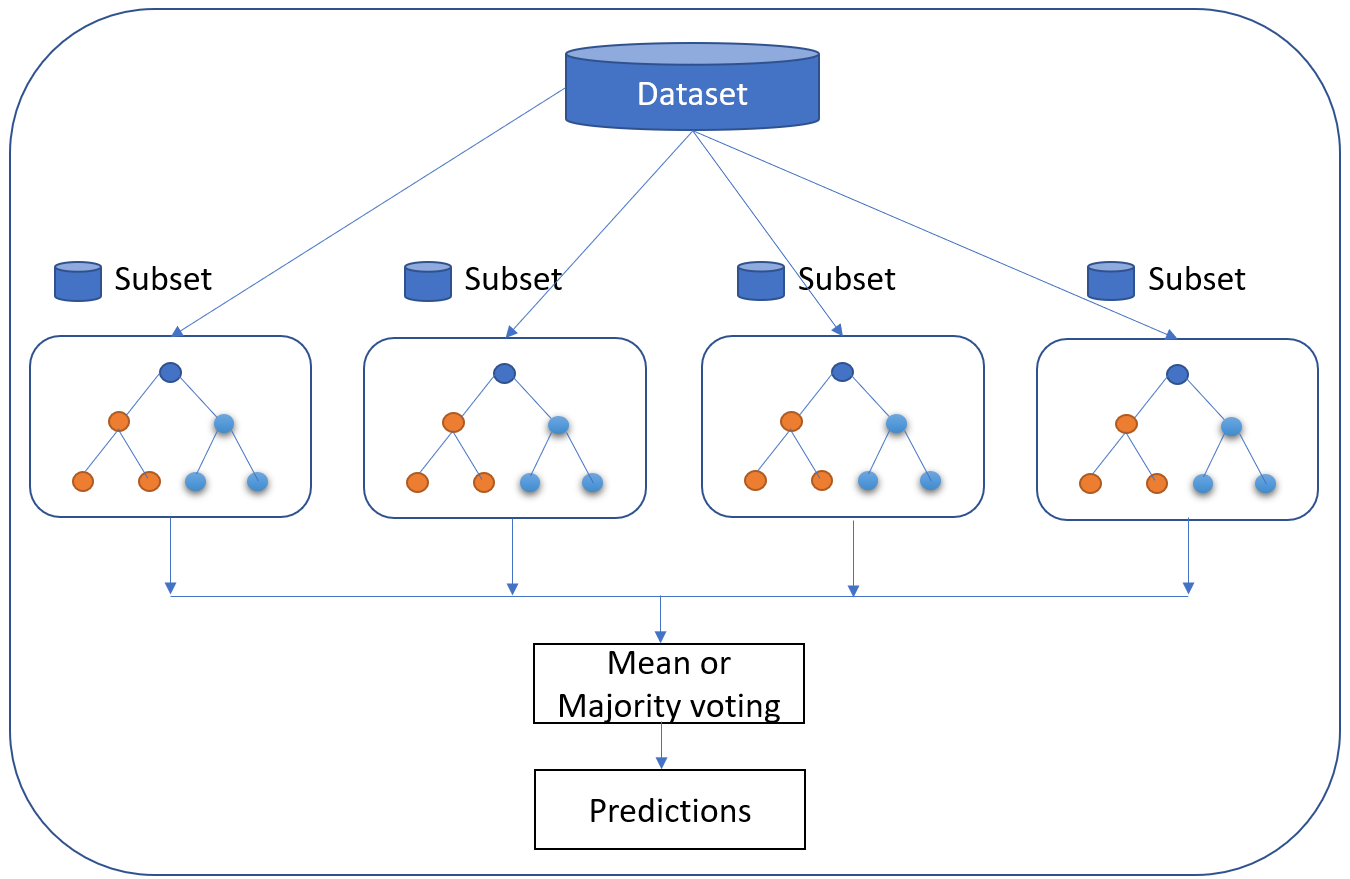
Si les arbres individuels peuvent être des "apprenants faibles". le principe de la forêt aléatoire est qu'ensemble, ils peuvent constituer un seul "apprenant fort".
La popularité du modèle Random Forest s'explique par ses différents avantages :
- Précision et efficacité lors de l'exploitation de grandes bases de données
- Les arbres multiples réduisent la variance et le biais d'un ensemble plus petit ou d'un seul arbre.
- Résistant à l'overfitting
- Peut gérer des milliers de variables d'entrée sans suppression de variables
- Possibilité d'estimer les variables importantes pour la classification
- Fournit des méthodes efficaces pour l'estimation des données manquantes
- Maintien de la précision lorsqu'une grande partie des données est manquante
2. Modèle linéaire généralisé (GLM) pour deux valeurs
Le modèle linéaire généralisé (MLG) est un modèle plus complexe plus complexe du modèle linéaire général. Il reprend la comparaison des effets de plusieurs variables sur des variables continues effectuée par le modèle linéaire général. variables multiples sur des variables continues avant de puiser dans un ensemble de distributions différentes pour trouver le modèle "le mieux adapté".
Supposons que vous souhaitiez connaître le comportement d'achat des clients en matière de manteaux d'hiver. Une régression linéaire normale pourrait révéler que pour chaque différence négative de température, 300 manteaux d'hiver supplémentaires sont achetés. S'il semble logique que 2 100 manteaux supplémentaires soient vendus si la température passe de 9 à 3 degrés, il semble moins logique que si la température descend jusqu'à -20, ce chiffre augmente dans les mêmes proportions.
Le modèle linéaire généralisé réduirait la liste des variables, suggérant probablement une augmentation des ventes au-delà d'une certaine température et une diminution ou une stagnation des ventes lorsqu'une autre température est atteinte.
L'avantage de cet algorithme est qu'il s'entraîne très rapidement. L'avantage de cet algorithme est qu'il s'entraîne très rapidement. La variable réponse peut avoir n'importe quel type de distribution exponentielle. Le modèle linéaire généralisé est également capable de traiter des prédicteurs catégoriels, tout en étant relativement simple à interpréter. En outre, il permet de comprendre clairement l'influence de chacun des prédicteurs sur le résultat.et résiste assez bien à l'ajustement excessif. Cependant, il nécessite des ensembles de données relativement importants et est sensible aux valeurs aberrantes.
3. Modèle de gradient boosté (GBM)
Le modèle de gradient boosté produit un modèle de prédiction composé d'un ensemble d'arbres de décision. modèle de prédiction composé d'un ensemble d'arbres de décision (chacun d'entre eux étant un "apprenant faible", comme c'était le cas avec Random Forest), avant de le généraliser. Comme son nom l'indique, il utilise la technique d'apprentissage automatique "boosté", par opposition à l'apprentissage en sac utilisé par Random Forest. Il est utilisé pour le modèle de classification.
La caractéristique distinctive du GBM est qu'il construit ses arbres un par un. Chaque nouvel arbre contribue à corriger les erreurs commises par l'arbre formé précédemment, contrairement au modèle Random Forest, dans lequel les arbres n'ont aucune relation entre eux. Il est très souvent utilisé dans les classements par apprentissage automatique, comme dans les moteurs de recherche Yahoo et Yandex.
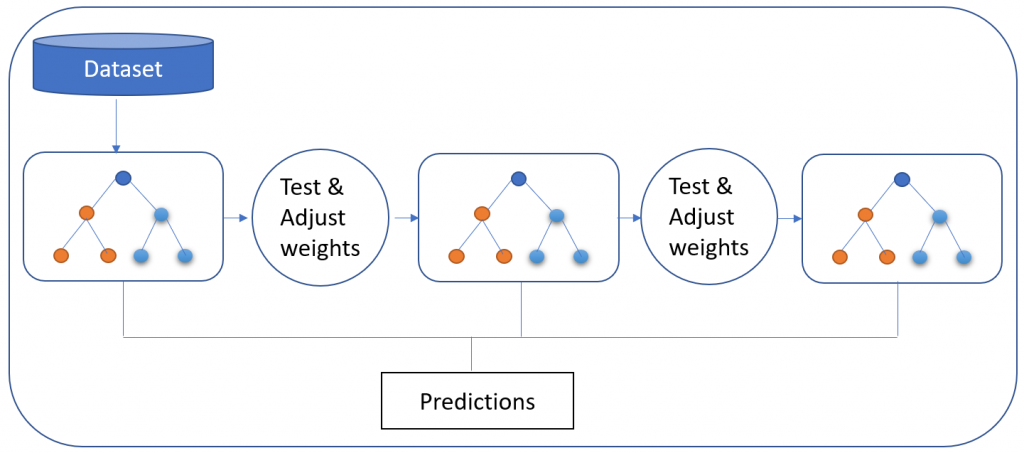
Grâce à l'approche GBM, les données sont plus expressives et les résultats comparatifs montrent que la méthode GBM est préférable en termes d'exhaustivité globale des données. Cependant, comme elle construit chaque arbre de manière séquentielle, elle prend également plus de temps. Cela dit, sa performance plus lente est considérée comme conduisant à une meilleure généralisation..
4. K-Means
Un algorithme à grande vitesse très populaire, K-means, consiste à placer les points de données non étiquetés dans des groupes distincts sur la base de similitudes. Cet algorithme est utilisé pour le modèle de regroupement.
Par exemple, Tom et Rebecca font partie du premier groupe, tandis que John et Henry font partie du deuxième groupe. Tom et Rebecca ont des caractéristiques très similaires, mais Rebecca et John ont des caractéristiques très différentes.
K-means tente de déterminer les caractéristiques communes des individus et de les regrouper. les regrouper. Cette méthode est particulièrement utile lorsque l'on dispose d'un vaste ensemble de données et que l'on cherche à mettre en œuvre un plan personnalisé - ce qui est très difficile à faire avec un million de personnes.
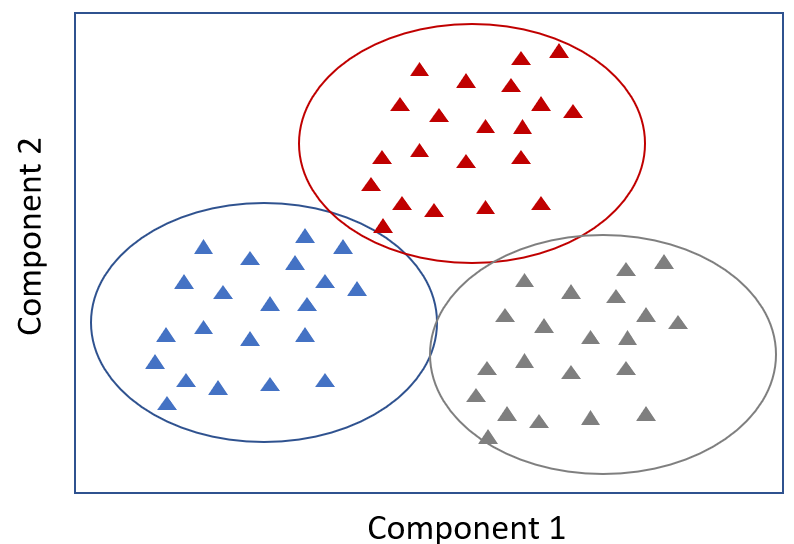
Dans le contexte de l'analyse prédictive pour les soins de santéde santé, un échantillon de patients pourrait être placés dans cinq groupes distincts par l'algorithme. Un groupe particulier partage de nombreuses caractéristiques : il ne fait pas d'exercice, il est de plus en plus souvent hospitalisé (trois fois une année, puis dix fois l'année suivante) et il présente un risque de diabète. Sur la base de ces similitudes, nous pouvons recommander de manière proactive un régime alimentaire et un programme d'exercices pour ce groupe.
5. Prophète
L'algorithme Prophet est utilisé dans les séries chronologiques et les modèles de prévision. Il s'agit d'un algorithme open-source développé par Facebook, utilisé en interne par l'entreprise pour les prévisions.
L'algorithme de Prophet est très utile pour la planification des capacités, notamment pour l'allocation des ressources et la fixation d'objectifs des. En raison du niveau de performance irrégulier des algorithmes de prévision entièrement automatisés et de leur manque de flexibilité, il a été difficile d'automatiser ce processus avec succès. D'autre part, les prévisions manuelles nécessite des heures de travail de la part d'analystes très expérimentés.r par des analystes très expérimentés.
Prophet n'est pas seulement automatique, il est aussi suffisamment souple pour intégrer des heuristiques et des hypothèses utiles. La rapidité, la fiabilité et la robustesse de l'algorithme face à des données désordonnées en ont fait un choix d'algorithme alternatif populaire pour les modèles d'analyse de séries temporelles et de prévisions. Les analystes experts comme les moins expérimentés en matière de prévision le trouvent précieux.
6. XGBoost
XGBoost, ou Extreme Gradient Boostingest un algorithme d'apprentissage automatique très performant, largement utilisé pour la classification et la régression. Il construit une série d'arbres de décision, chacun étant entraîné à corriger les erreurs commises par l'arbre précédent. XGBoost se distingue par son utilisation de la régularisationqui permet de contrôler l'ajustement excessif et d'améliorer la précision, en particulier sur les données structurées et tabulaires.
XGBoost est très efficace lorsque l'on travaille avec de grands ensembles de données et d'interactions de variables complexes. Il prend également en charge le traitement parallèlece qui permet des temps d'apprentissage plus rapides par rapport aux autres méthodes de boosting. C'est pourquoi il est souvent le premier choix dans les environnements de science des données compétitifs où la vitesse et la précision sont essentielles.
De nombreuses entreprises utilisent XGBoost pour prédiction du taux d'attrition des clients, la détection des fraudeset l'évaluation l'évaluation du risque de prêt. Dans la gestion de la chaîne d'approvisionnement, elle peut être appliquée pour prédire les retards de livraison sur la base de variables historiques et environnementales. Grâce à sa capacité à d'identifier les facteurs clés dans de grands ensembles de données, XGBoost est considéré comme l'un des algorithmes d'analyse prédictive les plus puissants utilisés aujourd'hui.
7. Transformateur de fusion temporelle (TFT)
Le transformateur de fusion temporelle est un algorithme plus récent conçu spécifiquement pour les les prévisions de séries temporelles. Il utilise l'apprentissage profond pour traiter les données séquentielles et peut incorporer des données historiques, statiques et futures connues pour générer des prévisions.
Le TFT diffère des modèles de séries temporelles traditionnels par l'utilisation de mécanismes d'attentionqui lui permettent de se concentrer sur les informations les plus pertinentes lorsqu'il fait des prédictions. Il est donc bien adapté aux scénarios dans lesquels plusieurs facteurs dynamiques ont un impact sur les résultats au fil du temps.
Les cas d'utilisation comprennent la prévision des ventes par catégories de produits, la planification des horaires du personnel dans les soins de santé sur la base de la demande historique, et la modélisation de la consommation d'énergie dans les bâtiments commerciaux. L'algorithme est particulièrement utile lorsque de nombreuses variables influencent les prévisions, telles que la saisonnalité, les changements de prix, les événements météorologiques et les différences régionales.
Le TFT se distingue par sa capacité à :
- Combiner plusieurs types d'entrées dans un seul modèle
- Mettre en évidence les variables sont les plus influentes
- Améliorer la précision des prévisions sur des ensembles de données à haute dimension
8. AutoML
AutoML, ou Automated Machine LearningAutoML est conçu pour simplifier la modélisation prédictive. Il automatise les étapes clés du processus d'apprentissage automatique, notamment la sélection de l'algorithme, l'ajustement des paramètreset l'évaluation du modèle. Cela permet aux équipes ne disposant pas d'une expertise technique approfondie de générer des modèles prédictifs fiables en une fraction du temps qu'il faudrait normalement.
Ce qui rend AutoML si précieux, c'est son accessibilité. En prenant en charge les tâches techniques lourdes en coulisses, il permet aux équipes marketing, aux responsables des opérations et aux analystes commerciaux de construire des modèles adaptés à leurs cas d'utilisation spécifiques, sans avoir à écrire de code. Cela inclut des tâches telles que l'évaluation des prospects, la détection des fraudeset la prévision de la demande d'inventaire.
AutoML est également une solution naturelle pour les plates-formes d'analyse intégrées telles que Logi Symphonyqui permet d'intégrer des modèles prédictifs directement dans les tableaux de bord et les flux de travail de l'entreprise. Il en résulte un temps de retour sur investissement plus rapideune plus grande évolutivité et une adoption plus large de l'analyse prédictive dans l'ensemble de l'organisation.
Des prévisions plus intelligentes grâce à l'analyse prédictive de Logi Symphony
Comment déterminer le modèle d'analyse prédictive le mieux adapté à vos besoins ? Vous devez commencer par identifier les questions prédictives auxquelles vous cherchez à répondreet, plus important encore, ce que vous souhaitez faire de ces informations. Considérez les points forts de chaque modèle, les défiset la façon dont chacun d'entre eux peut être optimisé avec différents algorithmes d'analyse prédictive, afin de décider de la meilleure façon de les utiliser pour votre organisation.
Si vous êtes prêt à passer de la théorie à l'action, Logi Symphony peut vous aider à mettre en œuvre ces modèles. Que vous souhaitiez intégrer des prévisions de données directement dans vos tableaux de bord ou permettre des prédictions en temps réel pour les utilisateurs finaux, Logi Symphony rend l'analyse prédictive plus accessible, plus évolutive et plus puissante pour les équipes de votre entreprise.
Cliquez ici pour obtenir une démonstration gratuite dès aujourd'hui..

Le guide définitif de l'analyse prédictive
Télécharger
Modèles d'analyse prédictive FAQ
Les modèles d'analyse prédictive aident les organisations à prendre des décisions plus éclairées et fondées sur des données en révélant les résultats futurs probables. Au lieu de réagir aux problèmes une fois qu'ils se sont produits, les entreprises peuvent anticiper les défis et les opportunités avant qu'ils ne se produisent. Par exemple, les modèles prédictifs peuvent identifier les clients qui risquent de se désabonner, prévoir la demande pour des produits spécifiques ou détecter les pannes d'équipement potentielles avant qu'elles ne perturbent les opérations. En transformant les données brutes en prévisions exploitables, l'analyse prédictive permet de réagir plus rapidement, d'allouer les ressources de manière plus intelligente et d'améliorer les performances globales de l'ensemble des services.
La précision des modèles d'analyse prédictive dépend de plusieurs facteurs clés, notamment la qualité des données, la sélection des algorithmes et la fréquence de mise à jour des modèles. Des données propres et bien structurées conduisent à des prédictions plus fiables, tandis que des sources de données diversifiées améliorent la représentativité. La précision des modèles s'accroît également grâce à une surveillance continue et à un recyclage au fur et à mesure que de nouvelles informations sont disponibles. Les entreprises mesurent généralement la précision à l'aide d'indicateurs tels que la précision, le rappel ou l'erreur absolue moyenne, en fonction du cas d'utilisation. Le maintien d'une boucle de rétroaction entre les prédictions et les résultats réels permet d'affiner les performances au fil du temps.
L'élaboration de modèles d'analyse prédictive nécessite de relever plusieurs défis courants. La mauvaise qualité des données, les valeurs manquantes et les formats incohérents peuvent réduire la précision et la fiabilité. Le choix de l'algorithme adapté au type de données et à l'objectif de l'entreprise requiert également une certaine expertise, car certains modèles sont plus performants pour les problèmes de classification, tandis que d'autres excellent dans les prévisions. En outre, les organisations doivent s'attaquer à des problèmes tels que l'ajustement excessif, le biais des données et le manque d'interprétabilité. La mise en place d'une solide gouvernance des données, de processus de validation cohérents et de rapports transparents peut contribuer à garantir la fiabilité et l'efficacité des modèles.
L'apprentissage automatique permet aux modèles d'analyse prédictive d'identifier automatiquement des modèles et des relations dans de vastes ensembles de données sans dépendre uniquement de la programmation manuelle. Les algorithmes apprennent à partir de données antérieures, détectent des tendances et font des prédictions qui s'améliorent au fil du temps, à mesure qu'ils sont exposés à de nouvelles informations. Les techniques courantes comprennent la régression, la classification et le regroupement, qui permettent aux systèmes de prévoir des résultats tels que le comportement des clients, les pannes d'équipement ou les tendances des ventes. En formant les modèles de manière itérative, les organisations peuvent continuellement affiner les prédictions, ce qui fait de l'apprentissage automatique un moteur essentiel de la réussite de l'analyse prédictive.
L'analyse prédictive a de vastes applications dans presque tous les grands secteurs d'activité. Dans le secteur financier, elle permet l'évaluation du crédit, la détection des fraudes et l'optimisation des portefeuilles. Les fabricants utilisent des modèles prédictifs pour la prévision de la demande, la planification de la chaîne d'approvisionnement et la maintenance des équipements. Les prestataires de soins de santé s'appuient sur l'analyse prédictive pour l'évaluation des risques des patients et la planification de traitements personnalisés. Les détaillants l'appliquent à l'optimisation des stocks et à l'analyse du comportement des clients. Chaque secteur bénéficie d'une meilleure anticipation, d'une réduction des coûts et d'une meilleure prise de décision, transformant ainsi les données en un avantage stratégique.