Parhaat ennakoivan analytiikan mallit ja algoritmit, jotka on hyvä tuntea

Ennustavat analyysimallit luodaan arvioimaan aiempia tietoja, paljastamaan malleja, analysoimaan trendejä ja hyödyntämään tätä tietoa tulevien trendien ennustamisessa.
Ennustavat analyysityökalut perustuvat useisiin erilaisiin malleihin ja algoritmeihin, joita voidaan soveltaa monenlaisiin käyttötapauksiin. Sen määrittäminen, mitkä ennakoivan mallintamisen tekniikat ovat parhaita yrityksellesi, on avainasemassa, kun haluat saada parhaan hyödyn irti ennakoivan analytiikan ratkaisusta ja tietojen hyödyntäminen oivaltavien päätösten tekemiseen.
Mieti esimerkiksi vähittäiskauppaa, joka haluaa vähentää asiakkaiden vaihtuvuutta. Niitä eivät ehkä palvele samat ennakoivan analytiikan mallit, joita sairaala käyttää ennustaessaan päivystyspoliklinikalle tulevien kymmenen päivän aikana tulevien potilaiden määrää.
Mitä ovat ennakoivan analytiikan mallit?
Ennustavat analyysimallit hyödyntävät aiempaa tietoa tulevien tapahtumien ennustamiseen, jolloin yritykset voivat tehdä ennakoivia, tietoon perustuvia päätöksiä. Nämä tietomallit hyödyntävät erilaisia tekniikoita piilotettujen mallien ja trendien paljastamiseksi.ja tarjoavat arvokasta tietoa strategista suunnittelua ja toiminnan tehokkuutta varten.
Haluatko mennä syvemmälle? Ilmainen resurssimme käydään läpi kaikki peruskäsitteistä edistyneisiin ennustetekniikoihin. Tämä opas auttaa sinua, olitpa sitten vasta aloittelemassa tai suunnittelemassa ennakoivan analytiikan laajentamista.
Mitkä ovat ennakoivan analytiikan mallien rakentamisen syötteet?
Ennustavan analytiikan mallien rakentaminen edellyttää useita keskeisiä panoksia:
- Historialliset tiedot
-
-
- Kuvaus: Analyysin kohteen kannalta merkitykselliset aiemmat tiedot.
- Esimerkkejä: Myyntitiedot, asiakkaiden käyttäytymistiedot, anturitiedot.
-
- Tietojen esikäsittely
-
-
- Kuvaus: Tietojen puhdistaminen ja valmistelu analyysia varten.
- Askeleet: Puuttuvien arvojen käsittely, tietojen normalisointi, poikkeavien arvojen poistaminen.
-
- Ominaisuus Engineering
-
-
- Kuvaus: Uusien muuttujien luominen, jotka auttavat mallia ymmärtämään tietoja paremmin.
- Esimerkkejä: Olemassa olevien ominaisuuksien yhdistäminen, vuorovaikutustermien luominen, päivämäärä-/aikaominaisuuksien poimiminen.
-
- Algoritmin valinta
-
-
- Kuvaus: Tehtävään sopivan koneoppimisalgoritmin valitseminen.
- Esimerkkejä: Lineaarinen regressio, päätöspuut, neuroverkot.
-
- Mallin koulutusdata
-
-
- Kuvaus: Ennustavan mallin kouluttamiseen käytetty tietokokonaisuus.
- Askeleet: Tietojen jakaminen harjoittelu- ja testausjoukkoihin tasapainoisen edustuksen varmistamiseksi.
-
- Arviointimittarit
-
-
- Kuvaus: Kriteerit mallin suorituskyvyn arvioimiseksi.
- Esimerkkejä: Tarkkuus, tarkkuus, palautus, F1-pisteet, keskimääräinen neliövirhe.
-
- Toimialatietämys
-
- Kuvaus: Erityisalan asiantuntemus mallin kehittämisen ohjaamiseksi.
- Esimerkkejä: Liiketoimintaprosessien, alan standardien ja asiaa koskevien säännösten ymmärtäminen.
Nämä panokset yhdessä auttavat rakentamaan vankkoja ja tarkkoja ennakoivan analyysin malleja.
Ennustavan analytiikan mallien tyypit
Ennustavat analyysimallit käyttävät historiatietoja, tilastollisia algoritmeja ja koneoppimistekniikoita ennustamaan tulevia tuloksia.. Yleisiä ennakoivia malleja ovat luokittelu (tietojen luokittelu), klusterointi (samankaltaisten tietojen ryhmittely) ja aikasarjamallit (tietojen analysointi ajan mittaan), joiden avulla voidaan tunnistaa malleja, trendejä ja mahdollisia tulevia tapahtumia.
1. Luokittelumalli
Luokittelumalli on tietyllä tavalla yksinkertaisin niistä useista ennustavan analytiikan malleista, joita aiomme käsitellä. Se luokittelee tiedot luokkiin sen perusteella, mitä se oppii historiatiedoista.
Luokittelumallit ovat parhaita kyllä- tai ei-kysymyksiin vastaamiseen, ja ne tarjoavat laajan analyysin, josta on apua päättäväisen toiminnan ohjaamisessa. Nämä mallit voivat vastata esimerkiksi seuraaviin kysymyksiin:
- Vähittäiskauppiaalle: "Onko tämä asiakas lähdössä pois?".
- Lainan tarjoajalle: "Hyväksytäänkö tämä laina?" tai "Onko todennäköistä, että tämä hakija laiminlyö maksujaan?".
- Verkkopankkipalvelun tarjoajalle: "Onko kyseessä vilpillinen maksutapahtuma?".
Luokittelumallin tarjoamien mahdollisuuksien laajuus - ja se, miten helposti se voidaan kouluttaa uudelleen uusilla tiedoilla - tarkoittaa, että sitä voidaan soveltaa monilla eri toimialoilla.
2. Klusterointimalli
Klusterointimalli lajittelee tiedot erillisiin, sisäkkäisiin älykkäisiin ryhmiin samankaltaisten ominaisuuksien perusteella. Jos sähköisen kaupankäynnin kenkäyritys haluaa toteuttaa kohdennettuja markkinointikampanjoita asiakkailleen, se voi käydä läpi satoja tuhansia tietueita luodakseen räätälöidyn strategian kullekin yksilölle. Mutta onko tämä tehokkainta ajankäyttöä? Todennäköisesti ei. Klusterointimallin avulla ne voivat nopeasti jakaa asiakkaat samankaltaisiin ryhmiin yhteisten ominaisuuksien perusteella ja laatia strategioita kullekin ryhmälle suuremmassa mittakaavassa.
Muita tämän ennakoivan mallinnustekniikan käyttötapoja voisivat olla lainanhakijoiden ryhmittely "älykkäisiin kauhoihin" lainaominaisuuksien perusteella, sellaisten kaupungin alueiden tunnistaminen, joilla on paljon rikollisuutta, ja SaaS-asiakastietojen vertailuanalyysi ryhmiin maailmanlaajuisten käyttömallien tunnistamiseksi.
3. Ennustemalli
Yksi yleisimmin käytetyistä ennakoivan analytiikan malleista, ennustemalli, käsittelee metristen arvojen ennustamista ja arvioi numeerisia arvoja uusille tiedoille historiatiedoista saatujen tietojen perusteella.
Mallia voidaan soveltaa kaikkialla, missä historiallisia numeerisia tietoja on saatavilla. Skenaarioita ovat mm:
- SaaS-yritys voi arvioida, kuinka monta asiakasta se todennäköisesti muuntaa tietyn viikon aikana.
- Puhelinkeskus voi ennustaa, kuinka monta tukipuhelua se saa tunnissa.
- Kenkäkauppa voi laskea, kuinka paljon varastoa sen pitäisi pitää käsillä, jotta se voi vastata kysyntään tietyn myyntikauden aikana.
Ennustemallissa otetaan huomioon myös useita syöttöparametreja. Jos ravintolan omistaja haluaa ennustaa, kuinka monta asiakasta hän todennäköisesti saa seuraavalla viikolla, malli ottaa huomioon tähän mahdollisesti vaikuttavat tekijät, kuten esimerkiksi Onko lähellä tapahtuma? Mikä on sääennuste? Onko jokin sairaus liikkeellä?
4. Outliers-malli
Outliers-malli on suunnattu tietokokonaisuuden poikkeaviin tietoihin. Sillä voidaan tunnistaa poikkeavat luvut joko yksinään tai yhdessä muiden lukujen ja luokkien kanssa.
- Tukipuhelujen määrä on kasvanut, mikä voi viitata tuotevirheeseen, joka saattaa johtaa takaisinvetoon.
- poikkeavien tietojen löytäminen liiketoimista tai vakuutushakemuksista petosten tunnistamiseksi.
- Epätavallisen tiedon löytäminen NetOps-lokeista ja merkkien havaitseminen lähestyvästä suunnittelemattomasta käyttökatkoksesta.
Outlier-malli on erityisen hyödyllinen vähittäiskaupan ja rahoituksen ennakoivassa analytiikassa. Esimerkiksi tunnistettaessa vilpillisiä liiketoimia malli voi arvioida summan lisäksi myös sijaintia, ajankohtaa, ostohistoriaa ja oston luonnetta (esimerkiksi 1000 dollarin elektroniikkaostos ei ole yhtä todennäköisesti vilpillinen kuin saman summan kirjojen tai yleishyödyllisten tuotteiden ostos).
5. Aikasarjamalli
Aikasarjamalli käsittää tallennettujen datapisteiden sarjan, jonka syöttöparametrina on aika. Se käyttää viimeisen vuoden tietoja numeerisen mittarin kehittämiseen ja ennustaa seuraavien kolmen tai kuuden viikon tietoja käyttäen tätä mittaria. Tämän mallin käyttötapauksia ovat esimerkiksi viimeisten kolmen kuukauden aikana päivittäin vastaanotettujen puhelujen määrä, myynti viimeisten 20 vuosineljänneksen ajalta tai sairaalaan viimeisten kuuden viikon aikana saapuneiden potilaiden määrä. Se on tehokas keino ymmärtää, miten yksittäinen mittari kehittyy ajan mittaan, ja sen tarkkuus ylittää yksinkertaiset keskiarvot. Siinä otetaan huomioon myös vuodenajat tai tapahtumat, jotka voivat vaikuttaa mittariin.
Jos kampaamon omistaja haluaa ennustaa, kuinka monta ihmistä todennäköisesti vierailee hänen liikkeessään, hän voi käyttää karkeaa menetelmää, jossa lasketaan keskiarvo kävijöiden kokonaismäärästä viimeisten 90 päivän ajalta. Kasvu ei kuitenkaan ole aina staattista tai lineaarista, ja aikasarjamallilla voidaan paremmin mallintaa eksponentiaalista kasvua ja sovittaa malli paremmin yrityksen trendiin. Se voi myös ennustaa useita hankkeita tai useita alueita samanaikaisesti, eikä vain yhtä kerrallaan.

Haluatko soveltaa näitä ennakoivan analytiikan malleja reaaliajassa?
Osoitteessa Logi Symphonyvoit upottaa ennustamisen, luokittelun ja poikkeamien havaitsemisen suoraan kojelautoihin ja sovelluksiin - ei tarvita datatieteiden tiimiä.
Katso, miten Logi Symphony tukee ennakoivaa analytiikkaa.
Mitä ovat ennakoivat algoritmit?
Ennakoivan analyysin algoritmit ovat laskennallisia menetelmiä, joita käytetään historiatietojen analysointiin. ja tehdä ennusteita tulevista tapahtumista. Nämä algoritmit, kuten lineaarinen regressio, päätöspuut ja neuroverkot, tunnistavat datan sisältämiä malleja ja suhteita, joiden avulla voidaan ennustaa tuloksia., mikä mahdollistaa tietoon perustuvan päätöksenteon ja strategisen suunnittelun.
Mitä koneoppimisalgoritmeja ennustamiseen käytetään?
Ennustamiseen käytettävät koneoppimisalgoritmit analysoivat historiatietoa, jotta ennustamaan tulevia tuloksia. Nämä algoritmit, kuten lineaarinen regressio, päätöspuut ja neuroverkot, tunnistavat datan sisältämiä kuvioita ja suhteita, mikä mahdollistaa tarkat ennusteet ja tietoon perustuvan päätöksenteon.
8 ennakoivan analytiikan algoritmityyppiä
Yleisesti ottaen ennakoivan analyysin algoritmit voidaan jakaa kahteen ryhmään: koneoppiminen ja syväoppiminen.
- Koneoppiminen liittyy strukturoituun dataan, jonka näemme taulukossa. Algoritmeja on sekä lineaarisia että epälineaarisia. Lineaariset algoritmit kouluttautuvat nopeammin, kun taas epälineaariset algoritmit on optimoitu paremmin niihin todennäköisesti kohdistuviin ongelmiin (jotka ovat usein epälineaarisia).
- Syväoppiminen on koneoppimisen osajoukko, joka on suositumpi äänen, videon, tekstin ja kuvien käsittelyssä.
Koneoppimiseen perustuvassa ennakoivassa mallintamisessa voidaan käyttää useita erilaisia algoritmeja. Alla on lueteltu joitakin yleisimpiä algoritmeja, joita käytetään edellä kuvattujen ennakoivan analytiikan mallien käyttämiseen.
1. Satunnainen metsä
Random Forest on ehkä suosituin luokittelualgoritmi, joka pystyy sekä luokitteluun että regressioon. Se pystyy luokittelemaan tarkasti suuria tietomääriä.
Nimi "Random Forest" johtuu siitä, että algoritmi on yhdistelmä päätöspuita. Kukin puu riippuu satunnaisvektorin arvoista, jotka on poimittu riippumattomasti samalla jakaumalla kaikille "metsän" puille. Jokainen puu kasvatetaan mahdollisimman suureksi.
Ennustavat analytiikka-algoritmit pyrkivät saavuttamaan mahdollisimman pienen virheen joko käyttämällä "tehostamalla" (tekniikka, joka säätää havainnon painoa edellisen luokittelun perusteella) tai "bagging" (jossa harjoitusnäytteistä luodaan satunnaisesti ja korvaavasti valittuja osajoukkoja).
Random Forest käyttää pussitusta. Jos sinulla on paljon näytedataa, voit harjoittelun sijasta ottaa osajoukon ja harjoitella sitä, ja ottaa toisen osajoukon ja harjoitella sitä (päällekkäisyys on sallittua). Kaikki tämä voidaan tehdä rinnakkain. Datasta otetaan useita näytteitä keskiarvon muodostamiseksi.
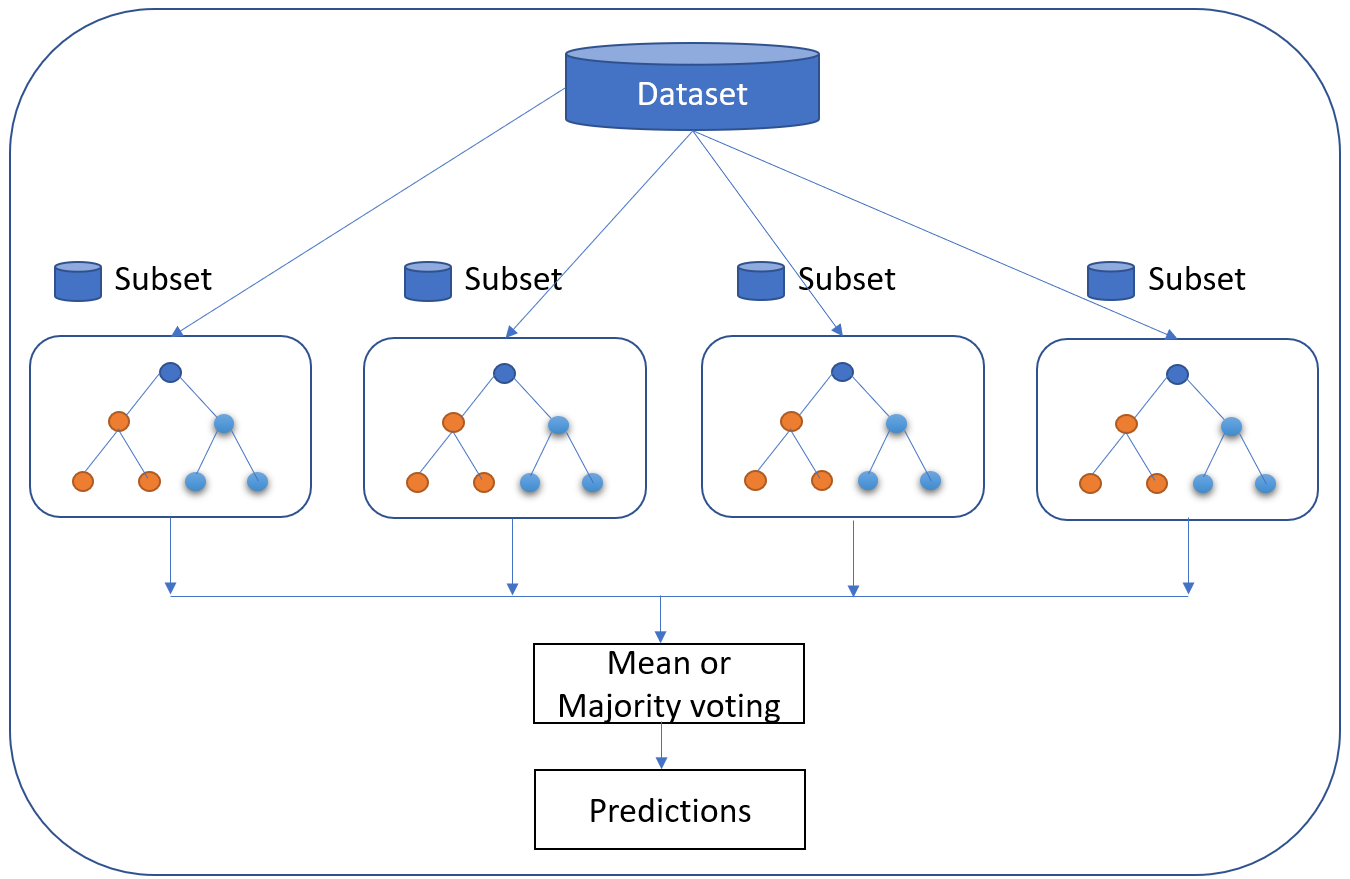
Vaikka yksittäiset puut saattavat olla "heikkoja oppijoita," Random Forestin periaatteena on, että yhdessä ne voivat oppia. muodostaa yhden "vahvan oppijan".
Random Forest -mallin suosio selittyy sen monilla eduilla:
- Tarkka ja tehokas, kun sitä käytetään suurissa tietokannoissa.
- Useat puut vähentävät pienemmän joukon tai yhden puun varianssia ja harhaa.
- Kestää ylisovittamista
- Voi käsitellä tuhansia syötemuuttujia ilman muuttujien poistamista.
- Voidaan arvioida, mitkä muuttujat ovat tärkeitä luokittelussa
- Tarjoaa tehokkaita menetelmiä puuttuvien tietojen estimointiin
- Säilyttää tarkkuuden, kun suuri osa tiedoista puuttuu.
2. Yleistetty lineaarinen malli (GLM) kahdelle arvolle.
Yleistetty lineaarinen malli (Generalized Linear Model, GLM) on enemmän monimutkainen muunnelma yleisestä lineaarisesta mallista. Siinä vertaillaan jälkimmäisen mallin vaikutusten vertailu useiden muuttujien vaikutusta jatkuviin muuttujiin ennen kuin vedetään joukosta erilaisia jakaumia "parhaiten sopivan" mallin löytämiseksi.
Oletetaan, että olet kiinnostunut oppimaan asiakkaiden ostokäyttäytymisestä talvitakkien osalta. Tavallinen lineaarinen regressio saattaisi paljastaa, että jokaista negatiivista asteen lämpötilaeroa kohden ostetaan 300 talvitakkia lisää. Vaikuttaa loogiselta, että 2 100 talvitakkia myydään lisää, jos lämpötila laskee 9 asteesta 3 asteeseen, mutta vähemmän loogiselta vaikuttaa se, että jos lämpötila laskee -20 asteeseen, määrä kasvaa täsmälleen saman verran.
Yleistetty lineaarinen malli kaventaisi muuttujien luetteloa ja viittaisi todennäköisesti siihen, että myynti kasvaa tietyn lämpötilan yläpuolella ja laskee tai tasaantuu, kun tietty lämpötila saavutetaan.
The Tämän algoritmin etuna on, että se harjoittelee hyvin nopeasti. Vastemuuttujalla voi olla mikä tahansa eksponenttijakauman tyyppi. Yleistetty lineaarinen malli pystyy käsittelemään myös kategorisia ennustajia, ja se on suhteellisen yksinkertainen tulkita. Tämän lisäksi se antaa selkeän käsityksen siitä, miten kukin ennustava tekijä vaikuttaa lopputulokseen., ja se on melko vastustuskykyinen ylisovittamiselle. Se vaatii kuitenkin suhteellisen suuria tietokokonaisuuksia ja on altis poikkeaville arvoille.
3. Gradient Boosted -malli (GBM)
Gradient Boosted Model tuottaa ennustemallin, joka koostuu päätöspuiden muodostamasta kokonaisuudesta. (joista jokainen on "heikko oppija", kuten Random Forestissa) ennen yleistämistä. Nimensä mukaisesti se käyttää "tehostettua" koneoppimistekniikkaa, toisin kuin Random Forestin käyttämä pussitus. Sitä käytetään luokittelumallissa.
GBM:n erityispiirre on, että se rakentaa puunsa puu kerrallaan. Jokainen uusi puu auttaa korjaamaan aiemmin koulutetun puun tekemiä virheitä - toisin kuin Random Forest -mallissa, jossa puilla ei ole yhteyttä toisiinsa. Mallia käytetään hyvin usein koneoppimisessa, kuten hakukoneissa Yahoo ja Yandex.
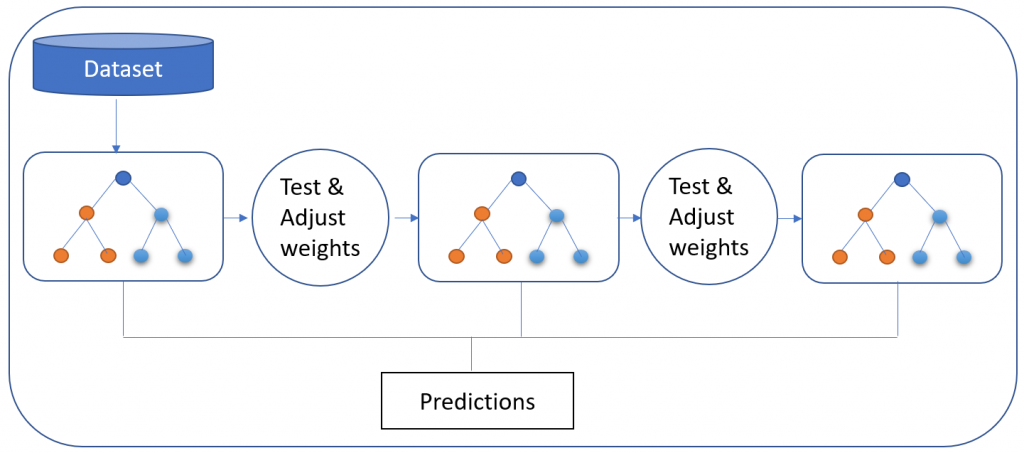
GBM-lähestymistavan avulla tiedot ovat ilmaisuvoimaisempia, ja vertailuanalyysitulokset osoittavat, että GBM-menetelmä on parempi tietojen yleisen perusteellisuuden kannalta. Koska se kuitenkin rakentaa jokaisen puun peräkkäin, se myös kestää kauemmin. Tästä huolimatta sen hitaamman suorituskyvyn katsotaan johtavan parempaan yleistettävyyteen..
4. K-Means
Erittäin suosittu nopea algoritmi, K-means, käsittää seuraavaa merkitsemättömien datapisteiden sijoittaminen erillisiin ryhmiin samankaltaisuuksien perusteella.. Tätä algoritmia käytetään klusterointimalliin.
Esimerkiksi Tom ja Rebecca ovat ryhmässä yksi ja John ja Henry ryhmässä kaksi. Tomilla ja Rebeccalla on hyvin samanlaiset ominaisuudet, mutta Rebeccalla ja Johnilla on hyvin erilaiset ominaisuudet.
K-means yrittää selvittää mitkä ovat yksilöiden yhteisiä ominaisuuksia ja ryhmittelee ne ryhmiin. yhteen. Tämä on erityisen hyödyllistä, kun käytössäsi on suuri tietomäärä ja haluat toteuttaa henkilökohtaisen suunnitelman - tämä on hyvin vaikeaa miljoonan ihmisen kohdalla.
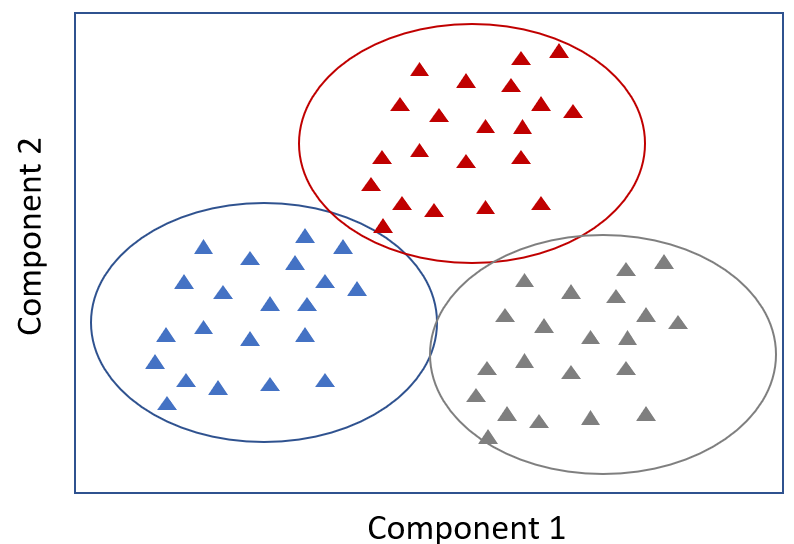
Seuraavassa yhteydessä terveydenhuollon ennakoiva analytiikkapotilaiden otoskoko voi olla algoritmi voi sijoittaa potilaat viiteen erilliseen klusteriin.. Yhdellä tietyllä ryhmällä on useita yhteisiä piirteitä: he eivät harrasta liikuntaa, heidän sairaalakäyntinsä lisääntyy (yhtenä vuonna kolme kertaa ja seuraavana vuonna kymmenen kertaa), ja heillä kaikilla on diabetesriski. Yhtäläisyyksien perusteella voimme ennakoivasti suositella tälle ryhmälle ruokavalio- ja liikuntasuunnitelmaa.
5. Profeetta
Prophet-algoritmia käytetään aikasarja- ja ennustemalleissa. Se on Facebookin kehittämä avoimen lähdekoodin algoritmi, jota yritys käyttää sisäisesti ennustamiseen.
Profeetta-algoritmista on paljon hyötyä kapasiteettisuunnittelussa, kuten esim. resurssien jakaminen ja myyntitavoitteen asettaminens. Täysin automatisoitujen ennustealgoritmien epäjohdonmukaisen suorituskyvyn ja joustamattomuuden vuoksi tämän prosessin onnistunut automatisointi on ollut vaikeaa. Toisaalta manuaalinen ennustaminen vaatii tuntikausien työpanosta.rin kokeneilta analyytikoilta.
Profeetta ei ole vain automaattinen; se on myös tarpeeksi joustava sisällyttääkseen heuristiikkoja ja hyödyllisiä oletuksia.. Algoritmin nopeus, luotettavuus ja kestävyys sotkuisten tietojen käsittelyssä ovat tehneet siitä suositun vaihtoehtoisen algoritmivalinnan aikasarja- ja ennusteanalyysimalleihin. Sekä asiantuntija-analyytikot että ennustamiseen vähemmän perehtyneet pitävät sitä arvokkaana.
6. XGBoost
XGBoost tai Extreme Gradient Boostingon suorituskykyinen koneoppimisalgoritmi, jota käytetään laajalti sekä luokitteluun että regressioon. Se rakentaa sarjan päätöspuita, joista jokainen koulutetaan korjaamaan edellisen puun tekemät virheet. XGBoost erottuu edukseen, koska se käyttää seuraavia menetelmiä regularisointia, joka auttaa hallitsemaan ylisovittamista ja parantamaan tarkkuutta - erityisesti strukturoiduissa, taulukkomuotoisissa tiedoissa.
XGBoost on erittäin tehokas työskenneltäessä seuraavien kanssa suurten tietokokonaisuuksien ja monimutkaisten muuttujien vuorovaikutusten kanssa. Se tukee myös rinnakkaista käsittelyämikä mahdollistaa nopeamman harjoittelun verrattuna muihin boosting-menetelmiin. Tämän vuoksi se on usein paras valinta kilpailukykyisissä datatieteen ympäristöissä, joissa sekä nopeus että tarkkuus ovat kriittisiä.
Monet yritykset käyttävät XGBoostia asiakkaiden poistuman ennustamiseen, petosten havaitsemiseenja lainariskin arviointiin. Toimitusketjun hallinnassa sitä voidaan soveltaa ennustamaan toimitusviivästyksiä historiallisten ja ympäristömuuttujien perusteella. Sen ansiosta sen kyky tunnistaa keskeiset ajurit suurissa tietokokonaisuuksissa, XGBoostia pidetään yhtenä tehokkaimmista nykyisin käytössä olevista ennakoivan analyysin algoritmeista.
7. Ajallinen fuusiomuuntaja (TFT)
Temporal Fusion Transformer on uudempi algoritmi, joka on suunniteltu erityisesti seuraavia tarkoituksia varten aikasarjan ennustamiseen. Se käyttää syväoppimista peräkkäisten tietojen käsittelyyn, ja se voi sisällyttää historiallisia, staattisia ja tunnettuja tulevia syötteitä ennusteiden tuottamiseen.
TFT eroaa perinteisistä aikasarjamalleista siten, että siinä käytetään huomiomekanismejajoiden avulla se voi keskittyä olennaisimpaan informaatioon ennusteita tehdessään. Tämän vuoksi se soveltuu hyvin skenaarioihin, joissa useita dynaamisia tekijöitä vaikuttavat tuloksiin ajan mittaan.
Käyttökohteita ovat esimerkiksi myynnin ennustaminen eri tuoteryhmissä, henkilöstön aikataulujen suunnittelu terveydenhuollossa historiallisen kysynnän perusteella ja energiankulutuksen mallintaminen kaupallisissa rakennuksissa. Algoritmi on erityisen hyödyllinen kun ennusteeseen vaikuttavat monet muuttujat, kuten kausivaihtelut, hinnoittelun muutokset, sääilmiöt ja alueelliset erot.
TFT erottuu edukseen kyvyllään:
- Yhdistä useita syöttötyyppejä yhdessä mallissa
- Korosta, mitkä muuttujat vaikuttavat eniten
- Paranna ennustetarkkuus korkea-ulotteisissa tietokokonaisuuksissa
8. AutoML
AutoML tai Automaattinen koneoppiminenon suunniteltu poistamaan ennakoivan mallintamisen monimutkaisuus. Se automatisoi koneoppimisprosessin keskeiset vaiheet, kuten algoritmin valinta, parametrien virittäminenja mallin arviointi. Tämän ansiosta tiimit, joilla ei ole syvää teknistä asiantuntemusta, voivat luoda luotettavia ennustemalleja murto-osassa siitä ajasta, joka normaalisti kuluisi.
AutoML:n tekee niin arvokkaaksi sen helppokäyttöisyys. Koska se hoitaa teknisen työn kulissien takana, se antaa markkinointitiimeille, operatiivisille johtajille ja liiketoiminta-analyytikoille mahdollisuuden rakentaa malleja, jotka on räätälöity heidän erityistapauksiinsa - ilman koodin kirjoittamista. Tämä sisältää muun muassa seuraavat tehtävät liidien pisteytys, petosten havaitseminenja varaston kysynnän ennustaminen.
AutoML sopii myös luonnollisesti sulautettuihin analytiikka-alustoihin kuten Logi Symphony, jonka avulla ennustemallit voidaan integroida suoraan kojelautoihin ja liiketoiminnan työnkulkuihin. Tuloksena on nopeampi arvon saavuttaminen, parempi skaalautuvuus ja laajempi käyttöönotto ennakoivan analytiikan laajempi käyttöönotto koko organisaatiossa.
Älykkäämpää ennustamista Logi Symphony -palvelun tarjoaman ennakoivan analytiikan avulla
Miten voit määrittää, mikä ennakoivan analytiikan malli sopii parhaiten tarpeisiisi? Sinun on aloitettava tunnistamalla mihin ennakoiviin kysymyksiin haluat vastata, ja mikä tärkeintä, mitä haluat tehdä näillä tiedoilla. Harkitse vahvuudet kunkin mallin vahvuudet, haasteetsekä sitä, miten kutakin niistä voidaan optimoida erilaisilla ennakoivan analytiikan algoritmeilla, jotta voit päättää, miten niitä voidaan parhaiten käyttää organisaatiossasi.
Jos olet valmis siirtymään teoriasta toimintaan, Logi Symphony voi auttaa sinua ottamaan nämä mallit käyttöön. Halusitpa sitten upottaa tietojen ennustamisen suoraan mittaristoihisi tai mahdollistaa reaaliaikaiset ennusteet. loppukäyttäjille, Logi Symphony tekee ennakoivasta analytiikasta helpommin lähestyttävää, skaalautuvaa ja tehokkaampaa koko organisaatiosi tiimeille.
Klikkaa tästä päästäksesi aloittamaan ilmainen demo tänään.

Ehdoton opas ennakoivaan analytiikkaan
Lataa nyt:
Ennakoivan analytiikan mallit FAQ
Ennustavat analyysimallit auttavat organisaatioita tekemään tietoon perustuvia, tietoon perustuvia päätöksiä paljastamalla todennäköiset tulevaisuuden tulokset. Sen sijaan, että yritykset reagoivat ongelmiin niiden ilmaantumisen jälkeen, ne voivat ennakoida haasteita ja mahdollisuuksia jo ennen niiden toteutumista. Ennustavat mallit voivat esimerkiksi tunnistaa asiakkaat, joilla on riski vaihtaa asiakkaita, ennustaa tiettyjen tuotteiden kysyntää tai havaita mahdolliset laiteviat ennen kuin ne häiritsevät toimintaa. Tekemällä raa'asta datasta käyttökelpoista ennakointia ennakoiva analytiikka mahdollistaa nopeamman reagoinnin, älykkäämmän resurssien kohdentamisen ja vahvemman kokonaissuorituskyvyn kaikilla osastoilla.
Ennakoivan analytiikan mallien tarkkuus riippuu useista avaintekijöistä, kuten tietojen laadusta, algoritmin valinnasta ja siitä, kuinka usein malleja päivitetään. Puhtaat, hyvin jäsennellyt tiedot johtavat luotettavampiin ennusteisiin, kun taas monipuoliset tietolähteet parantavat edustavuutta. Mallien tarkkuus kasvaa myös jatkuvalla seurannalla ja uudelleenkoulutuksella, kun uutta tietoa tulee saataville. Yritykset mittaavat tarkkuutta tyypillisesti käyttämällä mittareita, kuten tarkkuutta, palautusta tai keskimääräistä absoluuttista virhettä, käyttötapauksesta riippuen. Ennusteiden ja todellisten tulosten välisen palautesilmukan ylläpitäminen auttaa parantamaan suorituskykyä ajan mittaan.
Ennakoivan analytiikan mallien rakentaminen edellyttää useiden yleisten haasteiden voittamista. Huono tietojen laatu, puuttuvat arvot ja epäjohdonmukaiset muodot voivat vähentää tarkkuutta ja luotettavuutta. Oikean algoritmin valitseminen tietotyyppiin ja liiketoimintatavoitteeseen vaatii myös asiantuntemusta, sillä jotkin mallit toimivat paremmin luokittelussa, kun taas toiset taas loistavat ennustamisessa. Lisäksi organisaatioiden on käsiteltävä ongelmia, kuten ylisovittamista, tietojen vääristymistä ja tulkinnanvaraisuuden puutetta. Vahvan tiedonhallinnan, johdonmukaisten validointiprosessien ja läpinäkyvän raportoinnin avulla voidaan varmistaa, että mallit pysyvät luotettavina ja tehokkaina.
Koneoppimisen avulla ennakoivan analytiikan mallit pystyvät automaattisesti tunnistamaan kuvioita ja suhteita suurista tietokokonaisuuksista ilman, että ne perustuvat pelkästään manuaaliseen ohjelmointiin. Algoritmit oppivat aiemmista tiedoista, havaitsevat trendejä ja tekevät ennusteita, jotka paranevat ajan myötä, kun ne saavat uutta tietoa. Yleisiä tekniikoita ovat regressio, luokittelu ja klusterointi, joiden avulla järjestelmät voivat ennustaa esimerkiksi asiakkaiden käyttäytymistä, laitevikoja tai myynnin suuntauksia. Kouluttamalla malleja iteratiivisesti organisaatiot voivat jatkuvasti tarkentaa ennusteita, mikä tekee koneoppimisesta keskeisen tekijän ennakoivan analytiikan onnistumiselle.
Ennakoivalla analytiikalla on laajoja sovelluksia lähes kaikilla tärkeimmillä toimialoilla. Rahoitusalalla se tukee luottopisteytystä, petosten havaitsemista ja salkun optimointia. Valmistajat käyttävät ennakoivia malleja kysynnän ennustamiseen, toimitusketjun suunnitteluun ja laitteiden kunnossapitoon. Terveydenhuollon tarjoajat luottavat ennakoivaan analytiikkaan potilaiden riskien arvioinnissa ja yksilöllisessä hoidon suunnittelussa. Vähittäiskauppiaat soveltavat sitä varaston optimointiin ja asiakkaiden käyttäytymisen analysointiin. Kukin toimiala hyötyy paremmasta ennakoinnista, kustannusten alentamisesta ja paremmasta päätöksenteosta, jolloin tiedosta tulee strateginen etu.